[OS] Process Scheduling
이 글은 포스텍 박찬익 교수님의 CSED312 운영체제 수업의 강의 내용과 자료를 기반으로 하고 있습니다.
OS는 핀토스만 아니면, 수업 내용도 별로 안 어렵고 책도 잘 되어있어서 참 좋다.
진도도.. 가끔식 폭주하는 걸 빼면 느린 편이라서 할만하다.
여하튼, 이 파트는 저번 중간고사 때 이것까지 들어가는 줄 알아서 열심히 외었더니, 시험 문제를 받아보니 “기말고사 때 출제” 라고 적혀있어서 좀 황당했다.
1. CPU Schedular
예전 포스트에서 배웠듯이, 한정된 자원으로 최대한의 성능을 이끌어내기 위해서는 scheduling이 필요하다.
이번 포스트에서는 이를 수행하는 알고리즘에 대해서 배운다.
알고리즘은 두 가지 분류 방법, 내지는 구현 방법이 있다.
첫 번째는 non-preemptive scheduling이다.
이는 어떤 프로세스가 CPU를 할당받으면 그 프로세스가 종료되거나, 입출력 요구가 발생하여 자발적으로 중지될 때 까지 계속 실행되도록 보장하는 방식을 의미한다.
두 번째는 preemptive scheduling이다.
이는 간단히 말해 필요에 따라 다른 프로세스에게서 CPU를 강제로 회수할 수 있는 방식을 의미힌다.
이 방식은 유용하긴 하지만 그만큼 여러가지 예외 처리를 해야해서 구현이 복잡해진다.
2. Basic Knowledge
본격적으로 알고리즘을 알아보기 전에, 간단한 배경 지식에 대해 알아보고 가자.
1. Definitions
- Task/Job
- User request
- Latency/respose time
- Task를 끝내는데 걸리는 시간
- Throughput
- Unit time에 끝나는 task의 수
- Overhead
- Schedular가 해야하는 extra work
- Fairness
- User들이 얼마나 동등한 performance를 가져가는가
- Predictability
- Performance의 일관성 (일관성이 있어야 예측하기 쉽다)
- Workload
- Set of tasks for system to perform
- Preemptive schedular
- Running task가 끝나기 전에 resource를 회수해올 수 있는 schedular
- Work-conserving
- Resource is used whenever there is a task to run (Task가 있는 한, resource를 사용해라 = CPU를 놀게하지 마라)
- Scheduling algorithm
- Input: Workload
- Ouput: Performance metric (throughput, latency)
- Task를 어떤 순서로 실행할 것인지 결정하는 알고리즘
2. Scheduling Policy Goals
- Minimize response time: Elapsed time to do a task/job
- Ex) elapsed time to
- echo a keystorke in editor
- compile a program
- run a large scientific problem
- Ex) elapsed time to
- Maximize throughput: # of tasks/job completed per second
- To achieve
- Minimize overhead
- Efficient use of system resource
- To achieve
- Fair: Share CPU among users in some equitable way
3. FIFO
FIFO, First in First out은 먼저 들어오는 task부터 먼저 처리하는 알고리즘이다.
먼저 들어온 걸 모두 처리해야 다음에 들어온 걸 처리할 수 있으므로, non-preemptive이다.
Pros & Cons
굉장히 간단하다는 장점이 있으나, 긴 처리시간의 프로세스가 선점되어버리면 나머지 프로세스들은 끝날때 까지 대기해야 한다는 단점이 있다.
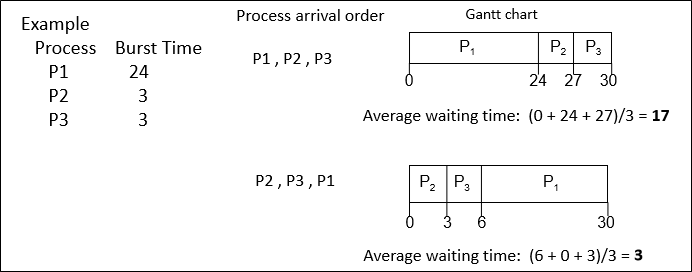
(waiting time은 P1, P2, P3 순서대로 계산한 것이다.)
예를 들어, P1, P2, P3가 한 번은 큰 순서대로, 다른 한 번은 작은 순서대로 들어왔다고 해보자.
작은 순서대로 들어오면 아주 빠르게 처리되는 반면, 큰 순서대로 들어오면 P1이 끝날 동안 P2, P3가 실행 시간 대비 매우 긴 시간을 기다려야 하므로 비효율 적이다.
이를 Convoy effect라고 한다.
4. SJF
최단 작업을 우선 실행하라
여기서 최단 작업이란 CPU burst time(연속적으로 CPU를 사용하는 시간)이 가장 짧은 process를 의미한다.
당연하게도, 가장 이상적이라 할 수 있다.
그런데 어떤 task를 실행하는 도중에, 그보다 더 짧은 task가 들어오면 교체해야 할까 말아야 할까?
만약 교체를 한다면 Preemptive SJF이고, 하지 않는다면 Non-preemptive SJF가 된다.
Non-preemptive SJF

P1이 실행되고 있는 동안, P2와 P3가 도착했다.
P1이 끝날 때, 현재 들어온 P2와 P3 중 P3가 더 짧으므로 P3를 실행한다.
Preemptive SJF
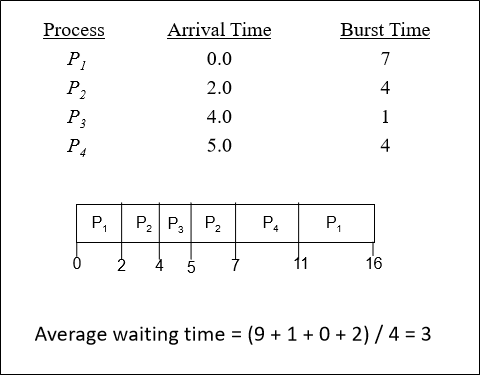
주의: Running task의 remaining time보다 새로 들어온 task의 busrt time이 짧을 때 preemtion이 일어난다
P1이 실행되던 도중, 2.0에 P2가 들어온다.
P1의 remaining time은 5이고, P2의 burst time은 4이므로 preemtion이 일어난다.
P2가 실행되던 도중, 4.0에 P3가 들어온다.
P2의 remaining time은 2이고, P3의 burst time은 1이므로 preemtion이 일어난다.
P3의 실행이 끝날 때, 현재 남아있는 task는 아래와 같다.
| Process | (Remaining) Burst Time |
|---|---|
| P1 | 5 |
| P2 | 2 |
| P3 | 4 |
따라서 P2를 실행해준다.
나머지 흐름은 쉽게 따라갈 수 있을 것이다.
Pros & Cons
- 장점
- Optimal
- Minimum average response time이 보장됨
- Preemptive SJF 가 항상 Non-preemptive SJF 보다 좋거나 같다.
- Optimal
- 단점
- Unfair
- Long-running job은 starvation을 겪을 수 있음
- Difficult to implement
- 어떻게 총 실행시간(burst time)을 예측하지?
- 코드의 길이를 보고 예측하거나, 미리 정보를 받아야 함
- Infeasible!!
- Unfair
FIFO vs SJF
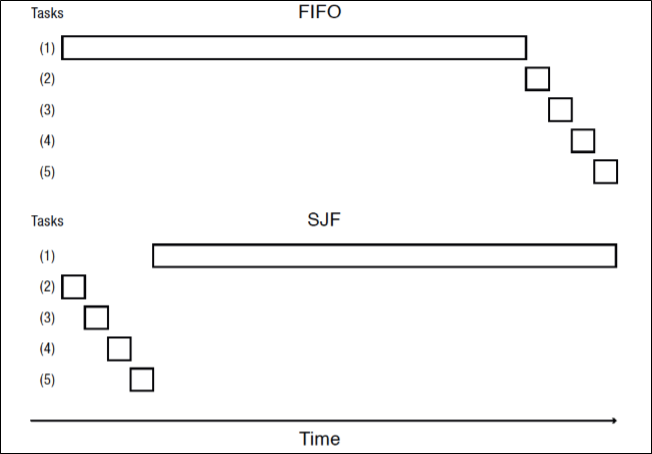
Convoy effect를 SJF에서는 효과적으로 막을 수 있음을 알 수 있다.
5. Round Robin(RR)
정해진 시간 할당량만큼 process를 할당한 뒤, 작업이 끝난 process는 ready queue의 가장 마지막에 가서 재할당을 기다린다.
정해진 시간을 time quantum이라고 한다.
이 Time quantum의 선정이 상당히 중요하다.
만약 너무 크게 잡아버리면 FIFO 같은 response time suffering이 발생한다.
반대로 만약 너무 작게 작아버리면 context switching이 너무 자주 일어나 overhead가 커지므로 throughput suffering이 발생한다.
보통 10~100 msec를 잡는 편이라고 한다.
간단한 예제를 통해 이해를 높여보자

Time quantum을 20으로 잡은 경우이다.
P1이 Time quantum 만큼을 소모하고 P2에게 CPU를 넘겨준다.
P2는 burst time이 17이므로, time quantum을 다 쓰지 못하고 곧바로 교체된다.
P3도 Time quantum 만큼 소모하고 P4 로 넘겨준다.
이후도 똑같은 흐름이다.
Pros & Cons
- 장점
- Better for short jobs
- If tasks are variable in size, RR approximates SJF
- 단점
- Poor when jobs are of the same length
- Quit long avg waiting time
FIFO vs RR
왜 same length 일 때 문제가 될까? FIFO와 비교해보면 이를 잘 알 수 있다.
100초가 걸리는 task 10개가 들어왔고, time quantum이 1초라고 해보자.
FIFO와 RR 둘 중 뭐가 더 response time이 좋을까?
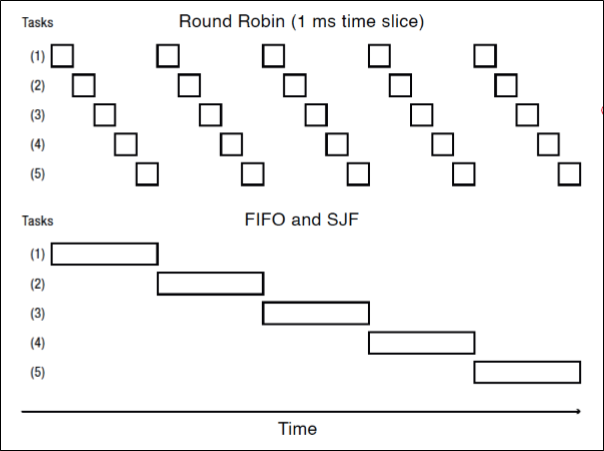
FIFO는 순차적으로 100초, 200초, 300초, 400초 …, 1000초 의 시간이 걸린다.
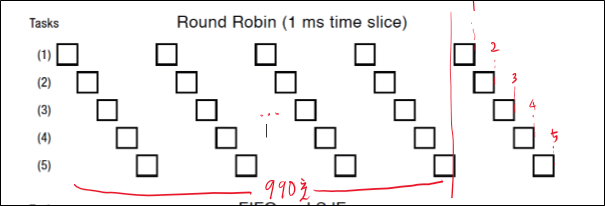
그러나, RR은 각 task가 100번의 turn을 얻어야 종료되므로, 991초, 992초, 993초, …, 1000초라는 괴랄한 시간이 걸린다.
Mixed Workload
Time quantum을 어떻게 잡냐에 따라 Same length 외에도 한가지 취약점이 더 존재할 수 있다.
바로 I/O-bound과 Compute-bound (CPU-bound)의 mixture를 schedule하는 경우이다.
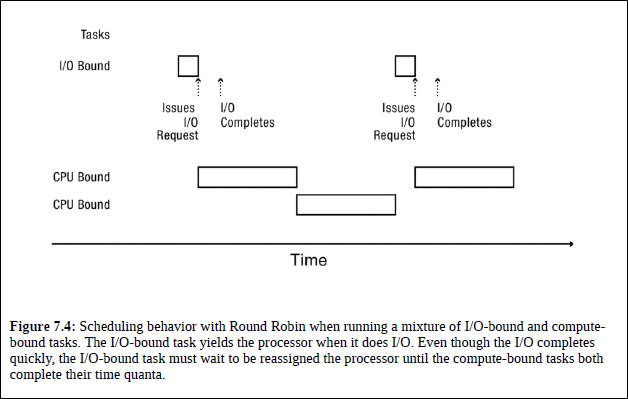
I/O-bound task는 짧은 시간 동안 I/O 결과를 처리하고, 다음 I/O operation을 위해 CPU를 yield하게 된다.
이때 time quantum이 길다면, I/O-bound task의 turn이 돌아오기까지 많은 시간이 걸릴 수 있다.
위 그림처럼 고작 2개의 CPU-bound task만 있어도 I/O-bound task의 waiting time은 매우 길어진다.
이해를 돕기 위해 간단한 예시를 하나 들어보겠다.
예를 들어, 메모장 프로그램과 다른 CPU-bound task 여러 개가 RR로 돌아가는 상황을 가정해보자.
메모장 프로그램은 글자를 하나 입력받으면 이걸 screen에 표시하고, 다음 글자를 받기 위해 I/O request를 날리고 yield한다.
만약 time quantum이 100ms이고, CPU-bound task가 한 5개쯤 된다면 다음 글자를 표시하는데 무려 500ms나 걸릴 수 있다.
6. Max-Min Fairness
그럼 이런 mixture는 어떻게 balancing해야 공평할까?
한 가지 추천되는 방법은 Max-Min Fairness를 맞추는 것이다.
Max-Min Fairness란 아래의 조건을 만족하는 scheduling을 말한다.
- 가장 적게 요구하는 곳부터 할당한다.
- 요구하는 것보다 많이 가질 수 없다
- 부족한 애들끼리 남은 양을 똑같이 할당받는다.
Mixture가 있을 때 max-min faireness가 어떻게 동작하는지 알아보자.
우선 short-running 또는 I/O-bound task에게 entire request를 준다.
이 task들을 다 채우고 남은 만큼의 resource를 CPU-bound task들에게 공평하게 나눠서 할당한다.
이때 할당 된 것보다 적은 양을 사용해서 extra work가 생기는 경우, 이를 떼어내서 아직 fully allocate되지 않는 task들에게 공평하게 재분배한다.
예를 들어, short-running 또는 I/O-bound task가 10%의 자원을 요구하고 있고, CPU-bound task가 3개가 각각 20%, 40%, 40%를 요구하고 있다고 해보자.
그럼 Max-Min Fairness는 short-running 또는 I/O-bound task를 다 채우기 위해 10%를 할당한다.
그리고 남은 90%를 각 CPU-bound task에게 30%씩 할당한다.
이때 20%짜리가 10%만큼의 extra work를 만들고 있으므로, 이를 떼어내어 40%짜리의 CPU-bound task들에게 각각 5%씩 할당해준다.
근데 사실 이 알고리즘은 network load distribution을 위해 나온 알고리즘이다.
그래서 검색해보면 죄다 network 관련밖에 안 뜰 것이다. 덕분에 이해하는데 좀 시간이 걸렸다…
여하튼, 이 max-min fairness를 근사해서 구현한 것이 다음에 소개할 MFQ이다.
7. Multi-level Feedback Queue (MFQ)
핀토스에서 열심히 구현한 MFQ이다.
Windows, MacOs 같은 대부분의 commercial OS는 MFQ scheduling algorithm을 사용한다.
MFQ는 아래의 목표들을 동시에 만족시키기 위해 디자인 된 알고리즘이다.
- Responsive: Run short tasks quickly, as in SJF
- Low Overhead: Minimize the number of preemptions, as in FIFO, and minimize the time spent making scheduling decisions
- Starvation Free: All tasks should make progress, as in Round Robin
- Background Tasks: Defer system maintenance tasks, such as disk defragmentation, so they do not interfere with user work.
- Fairness: Assign (non-background) processes approximately their max-min fair share of the processor.
하지만 현실적으로 이걸 다 만족시키는 건 어렵기 때문에, reasonable한 정도로 타협을 맞추는 편이다.
MFQ는 근본적으로 RR의 확장판이다. Single queue가 아닌, multiple RR queue를 사용한 것이라 생각하면 된다.
이때 각각의 RR queue는 서로 다른 priority level과 time quantum을 가진다.
Priority가 높은 queue일수록 shorter time quantum을 가진다고 생각하면 된다.
Scheudling은 Non-empty hightest priority queue에서 Round Robin으로 task를 뽑아 실행하는 방식으로 이뤄진다.
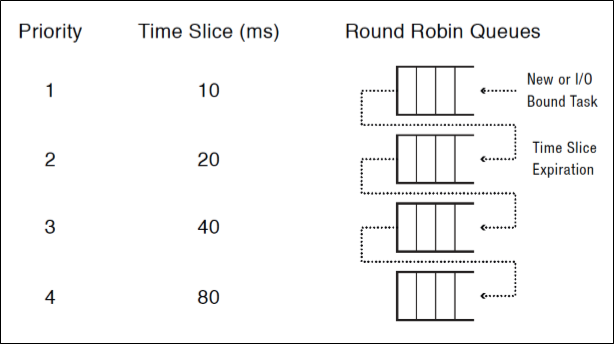
흥미로운 점은 task의 priority 할당이다.
Task의 burst time을 알 수 있다면 좋겠지만, 그럴 수 없기 때문에 MFQ는 다른 방식으로 priority를 구한다.
우선 hightest priority queue에 task를 넣는다.
만약 이 task가 time quantum이 지나고도 끝나지 않았다면, 다시 말해 time quantum보다 오래 실행되는 경우에는 lower priority queue로 이동시킨다.
반대로 time quantum이 지나기 전에 끝난다면, 다시 말해 time quantum보다 작게 실행되는 경우에는 higher priority queue로 이동한다.
이런 식으로 task를 이동시키면서 최대한 task의 실행 시간과 일치하는 곳에 위치하게 하는 것이다.
Properties
Priority 조절 과정에 의해 shorter job일수록 high priority queue에 위치하게 되므로 결과적으로 MFQ는 preemptive SJF를 근사하게 된다.
그렇기 때문에 SJF의 문제였던 starvation; I/O가 계속 들어온다면 CPU-bound는 CPU를 할당받을 수 없는 문제를 그대로 계승하고 있다.
8. Multiple-Processor Scheduling
MFQ를 multiprocessor에 적용하면 어떻게 될까? 꽤 많은 문제가 생긴다.
-
Contention for schedular spinlock
-
Cache slowdown due to ready list DS pining from one CPU to another
-
Limited cache reuse: thread’s data from last time it ran is often still in its old cache
Per-Processor Affinity Scheduling
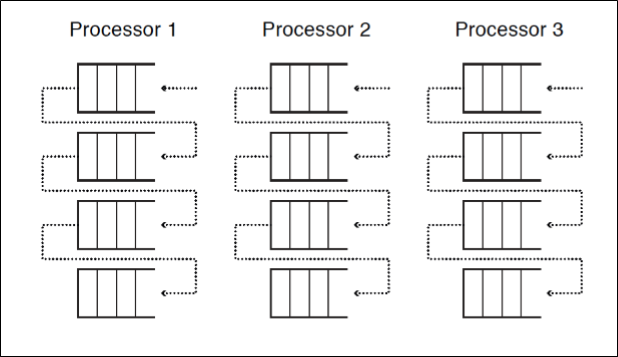
이 문제점을 해결하기 위해서 등장한 것이 Per-Processor Affinity Scheduling이다.
Per-processor란 각 processor마다 ready list(MFQ)를 둔다는 의미이다.
Affinity Scheduling이란 thread가 re-schedule 될 때 해당 thread가 이전에 할당됐던 processor에 다시 할당하는 sheduling policy를 말한다.
이는 위에서 지적했던 Limited cache reuse 문제를 해결하기 위함이다.
근데 이 경우 thread를 하나도 할당받지 못해 일을 안하는 idle processor가 생길 수 있다.
이는 idle processor가 다른 processor로부터 work를 훔쳐오는 rebalancing을 통해 해결할 수 있다.
9. Virtualization and Scheduling
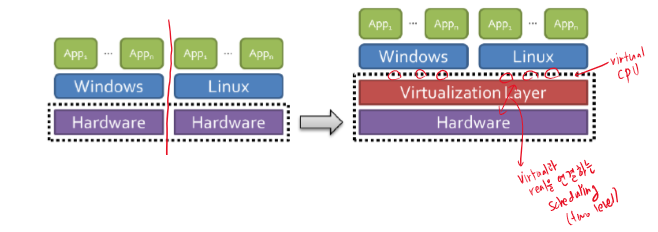
여러개의 OS를 지원하기 위해서는 HW와 OS 사이에 virtualization layer를 넣어야 한다.
이로 인해, virtualization layer는 여러 OS들의 scheduling result를 모아 다시 scheduling을 하는 two-level scheduling을 해야하고, 이는 성능 저하를 야기한다.