[OS] File System Implementation (1)
이 글은 포스텍 박찬익 교수님의 CSED312 운영체제 수업의 강의 내용과 자료를 기반으로 하고 있습니다.
아 진짜.. 공부해야 하는데 소설 보면서 뒹굴뒹굴 하고 있다..
갑자기 오토마타 진도도 폭주해서 할 것도 많은데 으아아아ㅏ
빨리 졸업하고 싶다..
1. Overview
지난 시간은 file system의 개념과 기본 구조에 대해서 배웠다.
이번 시간은 file system을 구현함에 알아야 하는 여러가지 issue와 해결법에 대해서 알아볼 것이다.
우선 file system을 구현함에 있어서 필요한 것들이 무엇인지 알아보자.
File system이 필수적으로 구현해야 하는 data strcuture는 다음과 같다.
- Directories
file name -> file metadata
- Store directories as files
- File metadata
how to find file data blocks
- Free map
list of free disk blocks
이 DS와 더불어, file system을 구현함에 있어서 마주해야 하는 challenges는 다음과 같다.
- Index strcuture
How do we locate the blocks of a file?
- Index granularity
What block size do we use?
- Free space
How do we find unused blocks on disk?
- Locality
How do we preserve spatial locality?
- Reliability
What if machine crashes in middle of a file system op?

여기서 index structure란, 파일이 disk상에서 어디에 있는지를 결정하는 구조이다.
Index strcuture가 정의되어야지만 디스크에 있는 파일에 접근할 수 있다.
한편 위의 그림에서 file number란 UNIX에서의 inode number와 같은 것으로 생각하면 된다.

Inode란, file header(file attributes except name)를 담는 data stucture이다.
모든 파일은 각자의 inode를 가지며, 각 inode는 해당하는 파일의 정보를 담고 있다고 보면 된다.
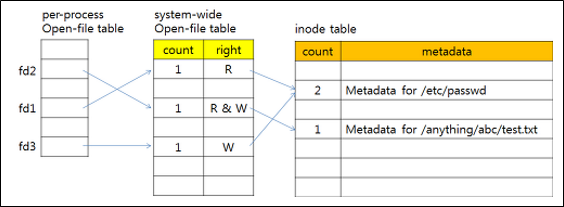
한편 Inode는 위 그림처럼 fixed-size inode array에 의해 관리된다.
이때 array의 index가 바로 i-number(inode number)인 것이다.
곧, directory는 file name to inode의 매핑을 저장한다고 생각하면 된다.
이에 관해서 저번 포스트에서 잠깐 언급했었다.
한편 File system challenges를 기반으로 file system components를 나누면 아래와 같다.
-
Disk management
-
Naming and directories
-
Efficiency and performance
-
Reliability and protection
우리는 오늘 이 중 위 3개를 알아볼 것이다.
2. Disk Management
File system은 아래 두 가지 정보를 추적해야 한다.
-
Where is your file data?
-
Where is free space?
그냥 심플하게 전체 file system에 대해서 순회하며 (1)번 정보를 구하면 자연스레 (2)번도 구할 수 있겠지만, 이는 굉장히 비효율적이다.
어떻게 해야 효율적으로 위 두 물음에 답할 수 있을까?
이번 챕터에서는 이에 대해 두 파트에 걸쳐 답할 것이다.
2.1 Free Space Management
2.1.1 Bitmap
Array of bits, with Nth bit indicating whether Nth block is free
Bitmap으로 free space를 표현하는 법이다.
- 장점
-
Easy to find contiguous space
-
Low space overhead
각 block 대비 차지하는 영역이 1bit 밖에 안됨
-
- 단점
- Requires extra space for a bitmap
- ex) 1 GB file system (2^30 / 2^12 = 2^18), 32KB bitmap
- ex) 1 PB file system (2^50), 32GB bitmap
- Not scalable
File system 크기가 크면 bitmap의 일부는 disk에 있어야 하고, 이는 현저한 성능 저하를 일으킴
- Requires extra space for a bitmap
이 단점을 극복하기 위해 나온 variation이 있다.
Breaking a bitmap into small chunks(e.g. smaller bitmaps) and keeping track of the number of bits set in each chunk
예를 들어, 1 PB file system (2^50), 32GB bitmap이 주어졌다고 하자.
이걸 10^6개의 bitmap으로 자르는 것이다.
그리고 각 bitmap이 얼마만큼의 free space를 갖고 있는지 표시하는 10^6개의 integer를 관리하는 것이다.
이러면 메인 메모리에 문제없이 들어간다!
2.1.1 Linked List
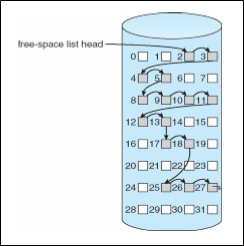
Linked list of free space
Free spaces를 linked list로 엮어서 관리하는 방법이다.
이 경우, bitmap과 다르게 extra space를 소모하진 않는다.
그러나 연속된 free space를 얻어내기가 어렵다.
2.2 Allocation
Allocation의 목표은 두 가지이다.
- Space on disk utilized effectively
- File can be accessed quickly
이 두 목표를 최대한 잘 만족하는 것이 좋은 allocation scheme이라 할 수 있겠다.
2.2.1 Contiguous Allocation
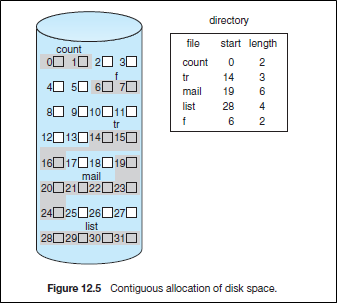
requires that each file occupy a set of contiguous blocks on the disk.
연속된 영역에 할당하는 방법이다.
FIle header에는 파일의 first sector와 그 길이만 표현해주면 파일이 어디에 위치하는지 알 수 있다.
- 장점
-
Fast sequential access
-
Easy random access
-
- 단점
-
External fragmentation
-
Hard to grow files
-
Extent
Contiguous Allocation를 약간 변형시킨 버전이다.
Contiguous blocks of disk(a.k.a Extent)를 allocation의 단위로 두는 것이다.
곧, 파일은 한개 이상의 extent로 이뤄지게 된다.
할당에 있어서 조금 더 선택지가 많아졌지만, large extent로 인한 internal fragmentation과 varying size로 인한 external fragmentation 문제는 피할 수 없다.
2.2.2 Linked Allocation
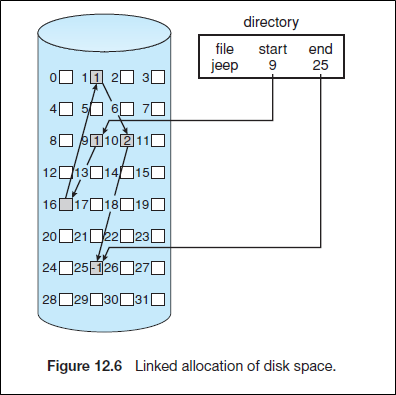
each file is a linked list of disk blocks; the disk blocks may be scattered anywhere on the disk
각 disk block을 pointer area / data area로 나누어 linked list를 구현한 것이다.
File header에는 시작 노드와 끝 노드의 pointer만 기록해주면 파일이 어디 block에 위치하는지 구할 수 있다.
이는 Contiguous Allocation의 문제를 훌륭하게 해결할 수 있다.
왜냐하면 Linked list로 구현하게 되면 임의의 위치의 block들을 이어붙일 수 있으므로 External fragmentation이 생기지 않고, 또 확장도 어렵지 않기 때문이다.
- 장점
-
Can grow files dynamically
-
Free list is similar to a file
-
No waste of space
-
- 단점
- random access: horrible
매번 linked list를 탐색해야 하므로, 엄청나게 느리다. 게다가 각 pointer는 모두 disk에 있다!
- unreliable: losing a block means losing the rest
중간에 끊겨버리면 탐색을 할 수 없음
- space overhead
각 block에 pointer를 저장하기 위한 공간이 필요함
- random access: horrible
FAT
Linked Allocation의 구현을 살짝 수정한 버전이다.
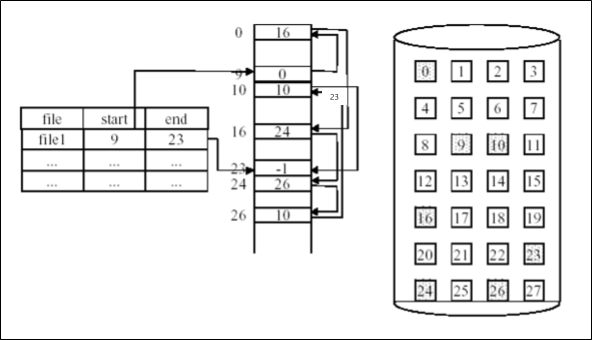
Random access performance를 올리기 위해, pointer를 separate linked list로 관리하는 것이다.
이러면 탐색을 main memory에서 할 수 있으므로 상대적으로 random access의 속도가 올라간다.
- 장점
-
Easy to find free block
-
Easy to append to a file
-
Easy to delete a file
-
- 단점
-
Small file access is slow
- Random access is stil very slow
기존 구현보다는 빠르지만, 일단 탐색해야 한다는 것 자체가 성능 저하를 야기한다.
- Poor locality
FAT implementations typically use simple allocation strategies such as next fit. These can lead to badly fragmented files
-
2.2.3 Single-Level Indexed Allocation
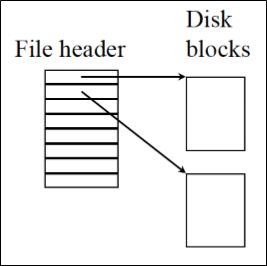
Each file is array of scattered disk block
Linked Allocation의 random access 문제를 해결하기 위해, array를 통해 efficient direct access를 지원하는 방법이다.
- 장점
-
Can grow up to a limit
-
Random access is fast
-
No external fragementation
Any block can be allocated
-
- 단점
- Clumsy to grow beyond the limit
처음에 array 사이즈를 고정해서 만들기 때문에, array size의 한계에 다다르면 확장하기가 어렵다.
- Still lots of seeks
Due to scattered disk blocks, need to seek many times
- Clumsy to grow beyond the limit
2.2.4 Multi-Level Indexed Allocation
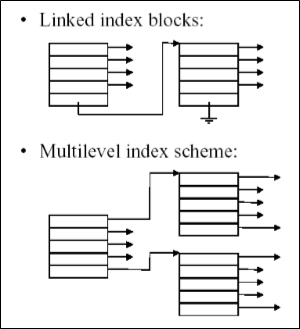
Size를 넘어서 확장하기 어렵다는 문제를 해결하려면 multi-level을 도입하면 된다.
이전에 배웠던 multi-level page table과 동일한 방식이다.
다만 구현이 두가지로 나뉘는데, 하나는 linked list로 구현하는 방식이고 하나는 multilevel index로 구현하는 방식이다.
2.2.5 Combined Scheme
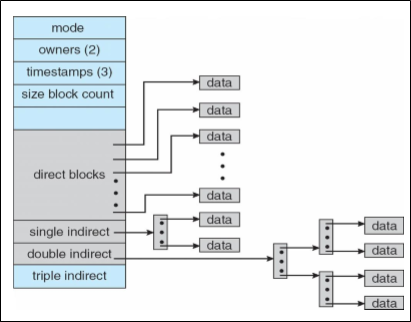
Unix에서는 Multi-Level Indexed Allocation을 변형한 combined scheme을 사용한다.
각 레벨 별로 관리를 하는 것이 핵심 아이디어이다.
이 구현은 확장하기도 쉽고, 작은 파일이든 큰 파일이든 효율적으로 할당할 수 있다는 장점이 있다.
그러나 아직도 lots of seeks 문제는 해결하지 못했다.
간단한 예제를 통해 이해도를 높여보자.
Q. Which block should be accessed?
- Block size = 1KB
- Pointer size = 4byte
-
Access byte offset = 9000
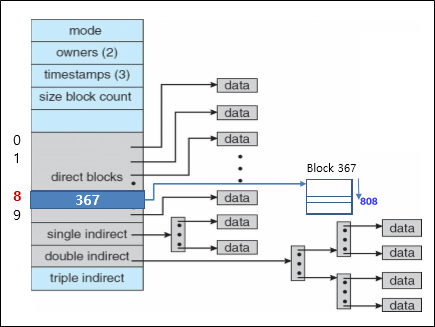
9000 = 1024*8 + 808
-
Access byte offset = 350000
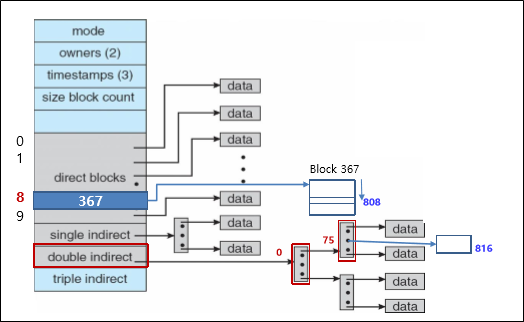
한 페이지(1KB=2^10)당 가리킬 수 있는 페이지의 수 = 2^10 / 2^2 = 2^8 = 256
350000 = 1024* 10 + 339760
339760 = 1024 * 256 + 77616
77616 = 1024 * 75 + 816
3. Naming and Directories
파일에 접근하는 방법(naming)에는 크게 3가지 종류가 있다.
- Use index
Ask users specify inode number
- Text name
name to index mapping
- Icon
icon to name mapping or icon to index mapping
또한 directory를 구현하는 방법에도 크게 3가지가 있다.
- Have a single directory for entire system
- Have a single directory for each user
- Hierarchical name spaces
지난 시간에 다 배웠던 것들이다.
오늘은 Hierarchical name spaces 구현에 대해 조금 더 깊게 알아보자.
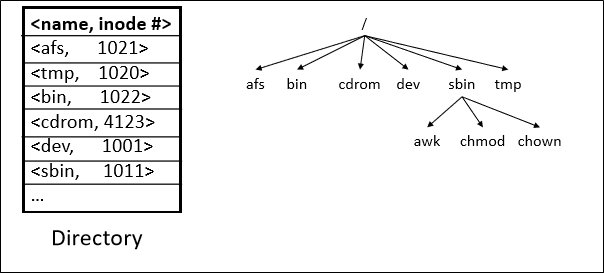
Hierarchical name spaces 내지는 Hierarchical UNIX는 위와 같은 계층형 구조를 말한다.
계층을 이루게 하는 핵심 요소는 directory이다.
Directory는 근본적으로 -name to inode mapping을 저장하는- 파일이다.
그냥 파일 읽듯이 읽을 수 있고, 파일 저장하듯 저장하면 된다.
한편 계층구조를 탐색하기 위해서는 몇가지 magic이 필요하다.
우선 root directory가 필요하다.
Root directory는 file system이 로드될 때, 자동적으로 inode #2에 할당된다.
이는 “/”로 접근할 수 있다.
이외에도
- Current directory: “.”
- Parent directory: “..”
- User’s home directory: “~”
등 여러가지 predefine path가 존재한다.
간단한 예제를 통해 이해도를 높여보자.
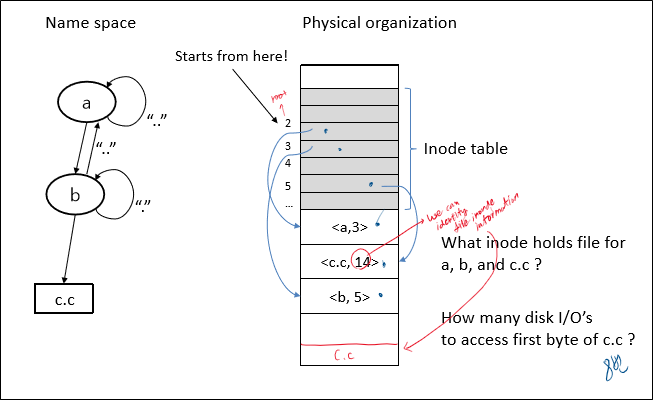
“/a/b/c.c”는 어떤 과정에 의해 찾아질까?
우선 “/” (root directory)가 2번에 있으므로, 여길 참조해서 a의 위치를 얻어낸다.
얻어내보니 3번이고, 3번을 참조해서 b의 위치를 얻어낸다.
얻어내보니 5번이고, 5번을 참조해서 c.c의 위치를 얻어낸다.
얻어내보니 14번이고, 14번을 참조해서 c.c의 저장 위치를 얻어낸다.
이후 c.c의 저장 위치에 접근하여 파일을 읽어들인다.
그런데 이처럼 매번 root directory부터 path를 명시하기에는 너무 귀찮다.
그래서 만약 path가 “/”로 시작하지 않는 경우, 자동적으로 path의 앞에 current working directory가 붙는다.
흔히 상대경로라고 한다.
자 이제, 지금까지 배운 내용을 종합해서 UNIX basic system call의 동작 과정을 자세하게 알아보자.
-
open-read-close cycle

우선 path를 분석하여 file inode를 얻어낸다.

namei는 위의 코드를 의미한다.
그냥 path를 파싱해서 inode를 얻어내는 것이다.
그리고 process wide descriptor table에 새로운 entry를 할당해준다.
이때, entry의 index가 fd가 된다.

Read는 block 단위로 이뤄진다.
위에서 배웠던 combined sheme을 적용해서, block 위치를 구해내면 된다.
읽은 데이터는 buffer cache로 들어오게 된다.
그냥 한번 읽어보면 금방 이해가 갈 것이다.
-
create-write-close cycle


위의 것과 비슷하다.
4. Efficiency and Performance
이제까지 block-allocatin과 directory-managment options에 대해 배웠다.
이제 어떻게 하면 Efficiency and Performance에 대해서 다룰 차례이다.
기본적으로 efficient use of disk space는 disk allocation and directory algorithms에 크게 영향을 받는다.
또한 file’s directory entry에 저장되는 데이터의 타입또한 영향을 미친다.
이게 무슨 소린가 싶을 건데, 간단히 “last access date” attribute를 생각해보자.
이 attribute는 파일에 접근할 때마다 갱신되어야 하기 때문에, 매 접근마다 파일의 메타데이터 또한 수정해서 다시 디스크에 써야한다.
이는 상당한 overhead를 발생시키기 때문에, 유용성 대비 성능 소모가 얼마나 되는지 잘 판단하여 해당 attribute를 유지할 지 심각히 고려해야 한다.
이런 식으로 각 파일에 얽힌 여러 data item들은 모두 성능 측면에서 심각한 고려가 필요하다는 의미이다.
이런 걸 다 고려해서 최대한 최적의 option을 골랐더라도, 아직 더 성능을 향상시킬 수 있다!
아래는 성능을 향상시킬 수 있는 방법들이다.
-
disk controller cache
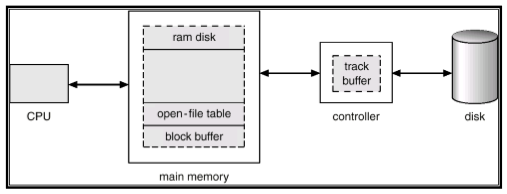
첫 번째 방법은 disk controller에 작은 on-board cache를 추가하는 방법이다.
이 cache는 한 번에 접근하는 track을 저장하기에 충분한 크기라서, operation이 disk를 접근하지 않고도 일어날 수 있게 해준다.
참고로 main memory의 block buffer는 읽어들여온 disk block을 저장하는 cache다.
-
free-behind and read-ahead
- Free-behind
Remove a page from the buffer as soon as the next page is requested. The previous pages are not likely to be used again and waste buffer space
- Read-ahead
A requested page and several subsequent pages that are likely to be requested after the current page is processes are read and cached
- Free-behind
-
Improve PC performance by dedicating section of memory as virtual disk, or RAM disk
Temporal file은 자주 생성되고 자주 삭제되고 자주 접근된다.
그래서 이런 파일들은 디스크에 저장하기 보단, main memory 쪽에 놔두는 것이 성능 측면이나 저장 측면이나 훨씬 낫다.
그래서 main memorty 일부를 virtual disk 혹은 RAM disk로 쓰자는 것이다.
-
Unified buffer cache
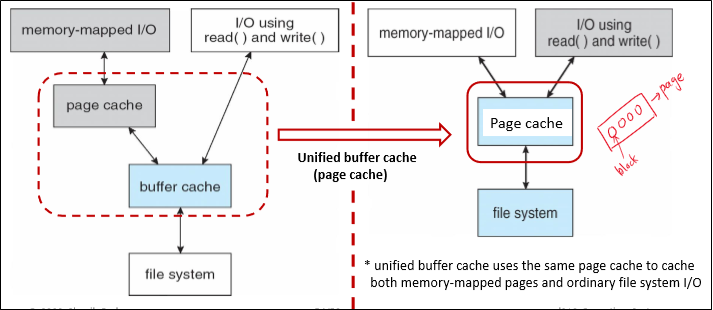
일부 시스템은 다시 쓰일 block 들을 저장하두는 buffer cache를 제공한다.
또 메인 메모리 상에서는 block보다 page 친화적이므로, 일부 시스템은 이를 page 형태로 저장하는 page cache를 제공한다.
위 두가지 cache가 주어졌을 때, 그냥 그대로 설치하면 좌측같이 서로 분리된 형태가 나온다.
그런데 이 경우, mmap I/O가 double caching이 발생하므로 매우 비효율적이다.
또한 쓸데없이 두 cache 간에 데이터를 옮긴다고 cycle을 소모하기도 한다.
그래서 그대신 두 cache를 합친 unified buffer cache를 주로 사용하는 편이다.