[OS] Address Translation
이 글은 포스텍 박찬익 교수님의 CSED312 운영체제 수업의 강의 내용과 자료를 기반으로 하고 있습니다.
핀토스 하는 김에 OS 글도 쓴다.
근데 OS는 PPT의 순서가 너무 꼬여있다는 생각이 자주 든다.
개인적으로 나는 주제 간의 흐름을 되게 중요하게 여기는데, OS는.. 음.. 여러 자료들을 참고해서 만들다 보니 흐름이 뚝뚝 끊기는 느낌을 많이 받는다.
최근에 공부한 File system이 가장 그랬다. 대체 왜 이 흐름에서 이 주제가 나오지? 하는게 너무 많았다.
수업할 때에도 내용을 건너뛰고, 나중에 돌아와서 보는 경우가 허다했다.
이렇게 흐름이 안좋으면 이리저리 재배치하면서 주제간의 흐름을 맞춰야 하기 때문에 다른 글을 쓰는 것에 비해 배 이상의 시간이 걸린다.
그래서 중간고사 때에도 OS 글이 가장 늦었었다.
개인적으로 AI ppt 가 흐름이 참 좋다고 생각한다. 수 년간 스탠포드에서 수정해와서 그런가 재배치할 필요없이 쭉 쓰기만 해도 좋은 흐름이 완성된다.
다만 분량이 너무 많아서 공부하기가 빡세다 ㅎ..
아! 그리고 요즘 구글이 뭔 짓을 하는지 최근 포스트가 검색 엔진에 등록이 안된다.
음.. 시험 치는 분들에게 도움이 되었으면 좋겠는데 검색을 못하니.. 시험 치기 전에는 등록될거라 믿는다 ㅎ
뭐 안되면 후배들이라도 보면 좋겠다. OS는 교수님이 달라지지도 않을테니 꽤나 도움이 될거라 생각한다.
또 뭐 방학 중에 아키도 복습 겸 포스팅 할 예정이니, 혹시 아키를 안들었다면 아마 나름 도움이 될 것이다.
겨울방학 때 김광선 교수님 랩에서 연참도 하니 모르면 물어봐야지.
1. What is Address Translation
Address Translation Concept
프로세스를 메모리에 올리는 상황을 생각해보자.
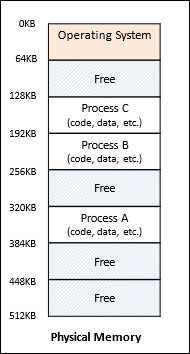
하나의 프로세스만 올리는 건 너무 비효율적이기 때문에, 필연적으로 위와 같이 여러 개의 프로세스를 올리게 된다.
이는 multiprogramming을 통해 성능을 비약적으로 향상시키지만, 그에 반하여 몇가지 복잡한 문제를 만든다.
이 중 우리가 알아볼 것은 Address Translation Issue이다.
Address Translation Issue
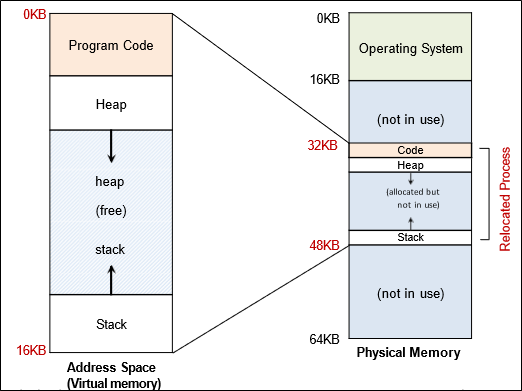
익히 배웠듯, 각 process는 고유한 virtual address space를 갖는다.
Process는 이 virtual address space의 주소를 기반으로 동작하나, 이는 가상 공간에 불과하므로 실제 공간(physical memory)의 주소로 번역되어야만 한다.
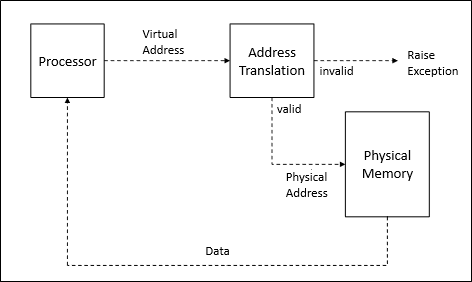
이것이 address translation의 개념이다.
그러면 이걸 어떻게 번역할 것인가?
Process가 0x0에 할당 됐다면 굉장히 쉽겠지만, 안타깝게도 임의의 위치에 할당된다.
그러면 이 할당 위치를 어떻게 추적할 것이며, 애초에 어떻게 할당해야 하는가?
또 하나의 중요한 문제는 Protection issue다.
Protection을 위해서는 다른 process의 주소로의 번역을 막아 간단히 구현할 수 있겠지만, 그러면 어떻게 sharing을 구현할 것인가? 라는 새로운 문제를 낳는다.
이런 수많은 머리 아픈 문제들이 address translation과 얽혀있다.
일반적으로 address translation이 해결해야 하는 문제, 내지는 목표를 정리하면 다음과 같다.
- Memory protection
We need the ability to limit the access of a process to certain regions of memory
- Memory sharing
We want to allow multiple processes to share selected regions of memory
- Flexible memory placement
We want to allow the operating system the flexibility to place a process (and each part of a process) anywhere in physical memory
- Sparse address
We want to allow dynamic memory regions that can change in size over the course of the execution of the program
- Runtime lookup efficiency
Since hardware address translation occurs on every instruction fetch and every data load and store, we need effiecent runtime lookup
- Compact translation tables
We also want the space overhead of translation to be minimal
- Portability
Different hardware architectures make different implementation of translation. To make easily portable OS, it needs to be able to map from its (hardware-independent) data structures to the specific capabilities of each architecture
우리는 이번 시간에 이 목표들을 달성하기 위한 여러 방법론에 대해 배울 것이다.
Free Space Management
본격적으로 address translation을 공부하기 전, 기초 지식으로 process allocation 혹은 free space management에 대해 배우고 넘어가야 한다.
Process는 기본적으로 메모리 상에서 single contiguous section을 차지한다. (이후에 이 paging 등에 의해 이 명제는 깨진다)
그러면 새로운 process를 할당하기 위해선 충분한 single contiguous section이 확보되어야 한다.
그럼 충분한 single contiguous section, 즉 free space가 존재하는지 어떻게 알 수 있는가?
이와 관련된 방법론이 free space management다.
우선 Free space를 어떻게 추적하는지 알아보자.
마프에서 배웠듯이, 꽤 많은 방법이 존재한다.
그러나 OS에서는 그중 제일 간단한 free list에 대해서만 알아볼 것이다.
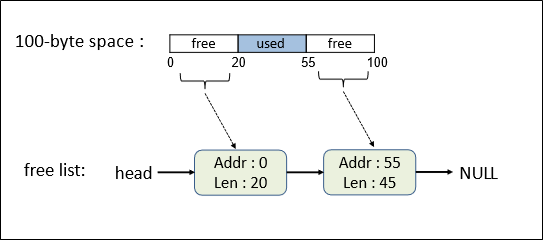
Free list는 free 영역을 list의 형태로 저장한다.
이때 free 영역은 시작 주소와 그 길이로 표현된다.
구체적인 구현법이 궁금하다면 마프 Lecture 19. Dynamic Memory Allocation: Advanced를 참고하면 된다.
Free 영역을 어떻게 추적하는지 알았으니, 어떻게 process를 할당하는지 알아볼 차례이다.
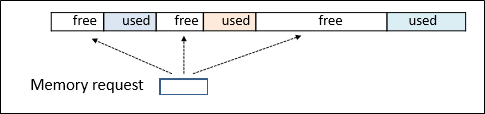
Process가 할당되기 위해서는 Process의 크기보다 큰 free 영역이 존재해야 한다.
그런데 그런 영역이 여러개 존재할 수 있다. 이 중에 어떤 곳에 할당해야 할까?
다양한 방법이 있지만, 딱 3가지에 대해서만 배운다.
- First fit
가장 먼저 만나는 할당 가능 영역에 할당한다.
- Best fit
할당 가능 영역 중, 가장 작은 것에 할당한다.
- Worst fit
할당 가능 영역 중, 가장 큰 것에 할당한다.
Best fit은 가장 메모리를 효율적으로 사용하지만, 전체 free list를 탐색해야 하므로 속도가 조금 느리다.
반면 First fit은 메모리를 조금 비효율적으로 사용하지만, free list를 조금만 탐색하므로 속도가 빠르다.
Worst fit은 말 그대로 최악이다. Best fit와 First fit에게 speed도, storage utilization도 진다.
External Fragmentation
그런데 이런 식으로 나눠서 할당을 하다보면 fragmentation(단편화)라는 피할 수 없는 문제와 마주하게 된다.
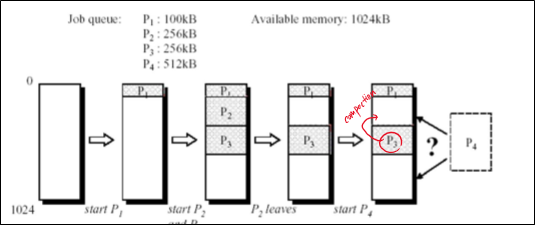
예를 들어 위와 같이 P4를 할당하려고 했을 때, 전체 공간은 충분하지만 연속된 공간이 부족해서 할당을 할 수가 없는 상황이 벌어진다.
이를 External Fragmentation이라고 한다.
이걸 해결하기 위한 가장 직접적인 방법은 빈 공간끼리 합치는 것(a.k.a Compatction)이다.
하지만 Compatction이 항상 가능한 것은 아니다.
Compatction을 하기 위해서는 reloaction이 dynamic하게 execution time에 이뤄질 수 있어야 한다.
또, 이동으로 인해 생길 수 있는 I/O 문제들(OS buffer로의 DMA 등)을 모두 해결해야만 한다.
설령 Compatction이 가능하다 해도 아직 비용이라는 큰 문제가 남는다.
만약 compaction을 모든 process를 한 쪽에 몰아버리는 식으로 구현한다면 그 비용이 꽤 비쌀 것이다.
그럼 compaction을 하지 않고 어떻게 External Fragmentation을 해결할 수 있을까?
근본적으로 External Fragmentation이 일어나는 이유는 process가 연속된 영역에 할당되어야 하기 때문이다.
그렇다면 process가 불연속 영역에 할당 될 수 있도록 하면, 다시 말해 process가 비어있는 아무 영역에나 들어갈 수 있으면 External Fragmentation을 해결할 수 있을 것이다.
이 아이디어에서 나오는 complementary techniques가 이후 2번에서 핵심적으로 다룰 주제인 segmentation과 paging이다.
왜 이런 테크닉이 출현해야 했는가? 를 이해하면 글의 흐름을 파악하는데 도움이 된다. 기억해두자.
Internal Fragmentation
한편 External이 있으면 Internal도 있어야 하지 않겠는가?
Internal Fragmentation의 정의는 다음과 같다.
메모리를 할당할 때 프로세스가 필요한 양보다 더 큰 메모리가 할당되어서 프로세스에서 사용하는 메모리 공간이 낭비 되는 상황
간단한 예제를 통해 이해도를 높여보자.
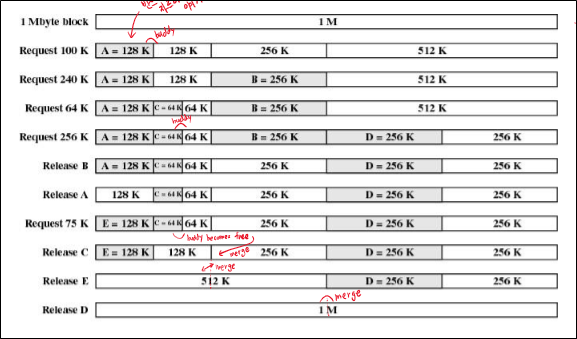
Buddy systems라는 Free Space Management algorithm이 있다.
이는 전체 메모리를 계속 반으로 자르면서, process가 들어갈 수 있는 최적의 영역을 찾아 할당하며, 할당 해제될 때, buddy(같은 크기를 가진 이웃)도 free 상태라면 compaction하는 알고리즘이다.
Request 100K index를 보자.
64K 에는 할당할 수 없으므로 128K에 할당하게 되는데, 실제 process의 크기는 100K이므로 28K의 공간이 낭비된다.
이게 Internal Fragmentation이다.
2. Flexible Address Translation
이번 소챕터에서는 본격적으로 Address Translation Technique에 대해 알아볼 것이다.
또한, Address Translation Technique이 제공하는 몇가지 기능들에 대해 알아볼 것이다.
아래는 기능의 예시들이다.
- Copy on write
- Zero on reference
- Fill on demand
- Demand paging
- Memory mapped files
- …
Base and Bound
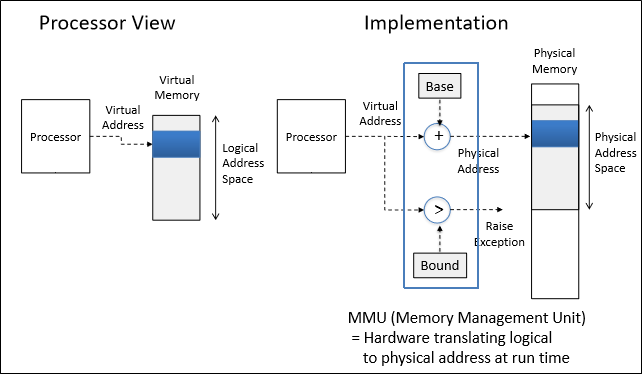
가장 간단하게 구현하는 방법은 base bound register를 이용하는 것이다.
Process를 single contiguous section에 할당하되, 할당 위치를 옮기는 것이다.
이때, Protection을 구현하기 위해 bound register가 도입된다.
Bound는 process의 length(내지는 크기)를 의미하는데, 만약 virtual address가 bound보다 크다면 이는 할당된 영역을 벗어난 접근이므로 접근을 차단한다.
Base + virtual address 와 bound를 비교하는게 아니다! Virtual address와 Bound를 직접 비교하는 것이다.
장단점은 꽤 명확하다.
- 장점
- Simple, fast
HW cost도 낮고, computational overhead도 낮고, context switch impl도 간단함
- Can reloacate in physical memory without changing process
- Simple, fast
- 단점
- Can’t share code/data with other processes
Bound를 넘어간 접근은 모두 차단하므로 다른 프로세스의 데이터에 접근이 불가능하므로
- Can’t grow heap/stack dynamically as needed
Base Bound 밖에 없으므로
- Can’t keep program from accidentally overwriting its own code
Code 영역을 구분하지 않으므로
- Can’t share code/data with other processes
Segmentation
Base Bound를 조금만 변형시키면 그 단점은 상당히 개선시킬 수 있다.
단순히 single pair of base and bound register를 유지하는 게 아니라, array of base and bound register를 유지하면 된다.
이게 바로 segmentation이다.
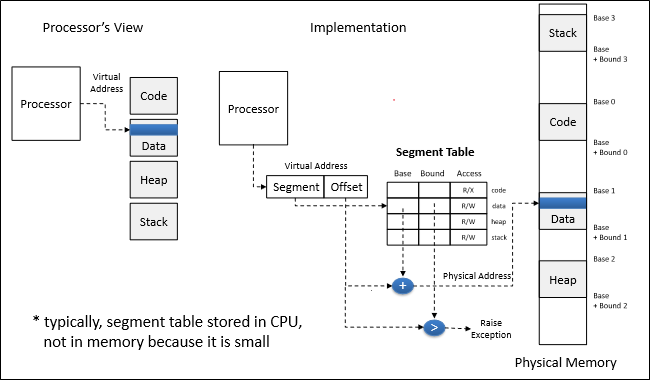
Segmentation은 prcoess를 여러 개의 연속된 영역(a.k.a segment)로 나눈다.
각 Segment는 start(base에 해당), length(bound에 해당), access permission으로 구성되어 있다.
이를 통해 Protection을 segment level로 끌어내릴 수 있으며, sharing과 code overwrite를 방지할 수 있다.
그럼 address translation은 구체적으로 어떻게 이루어질까?
우선 address를 segment part와 offset part로 나눈다.
Segment part는 segment table을 조회하기 위해 쓰이고, 조회해서 얻어낸 segment base를 offset과 더해서 physical address를 얻어낸다.
여기서 질문!
Segment table은 어디에 저장될까?
A. 그 크기가 작기 때문에, 일반적으로 CPU에 저장된다고 한다.
Segementation은 base bound의 많은 문제들을 해결했지만, 여전히 남아있는 문제가 많다.
- 장점
- Can transparently grow stack/heap as needed (efficient sparse address space)
Segment table의 bound 값을 조절하면 쉽게 늘릴 수 있다.
- Can easily share code/data segments btw processes
Segment table이 같은 값을 가리키게만 하면 쉽게 sharing을 구현할 수 있다.
- Can protect code segment from being overwritten
Code segement의 access permission을 read-only로 만들면 된다.
- Can detect if need to copy-on-write
- Can transparently grow stack/heap as needed (efficient sparse address space)
- 단점
- Complex memory management
- Large number of variable size
Segment의 크기가 다양하므로 그만큼 관리하기가 어렵다. 사이즈가 다양한 만큼 여전히 external fragmentation이 발생한다.
- Dynamically growing memory segments
다른 segment에 가로막혀 relocation을 해야하는 상황이 벌어질 수 있다.
- Large number of variable size
- Complex memory management
UNIX Fork and Copy On Write
Segementation이 제공하는 아주 중요한 additional feature 중 하나는 copy on write이다.
예전에 배웠던 UNIX fork system call을 떠올려보자.
Fork를 호출하면 UNIX는 parent process의 complete copy를 만들어서 child process를 생성한다.
그래서 fork는 overhead가 크다고 배웠지만, segmentation을 이용하면 효과적으로 fork를 구현할 수 있다!
방법은 간단하다.
Fork를 호출하면 parent process의 segment table을 복사해서 child process를 생성하고, 두 segment table의 access permission을 전부 Read only로 바꾸는 것이다.
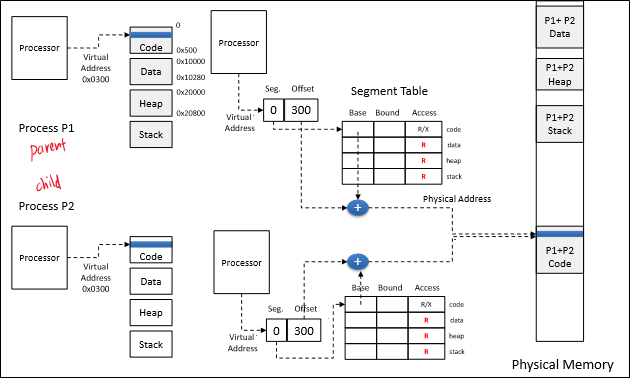
그러면 위와 같은 모습이 된다.
Copy를 하는 걸 피해 overhead를 크게 낮춘 것이다.
그런데 그러면 parent와 child는 같은 값을 가져야만 하는 걸까?
여기서 트릭이 사용된다.
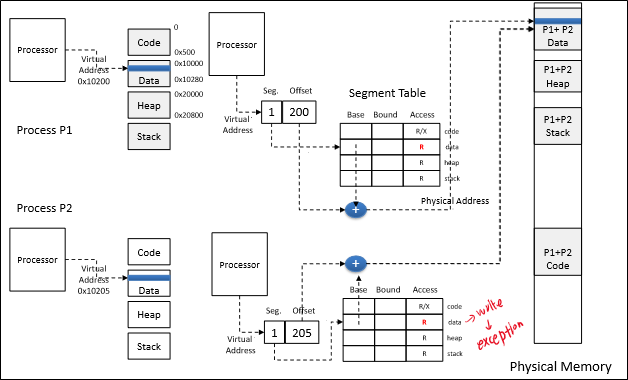
만약 두 process 중 하나가 write를 시도했다고 하자.
현재 모든 entry가 read-only이므로 exception이 일어날 것이다.
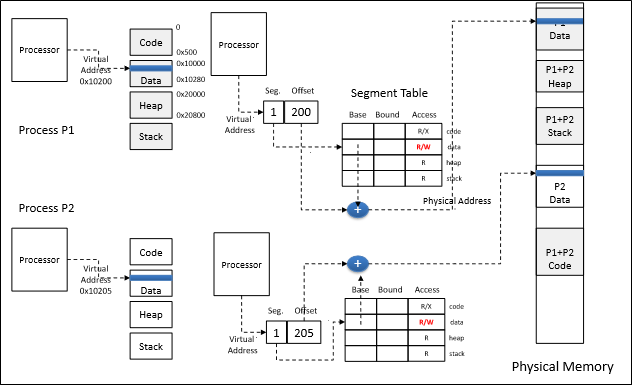
Exception handler는 copy on write임을 감지하여 parent의 segment를 복사해서 child에 할당하고, access permission을 R/W로 바꾼다.
그러면 parent와 child는 서로 다른 segement를 가지게 되었으므로 수정이 자유로워진다.
이런 식으로 분리가 되어야 할 때에만, 다시 말해 write가 일어나야 할 때에만 copy를 해주면 매우 효율적으로 fork를 구현할 수 있다.
Zero On Reference
Segmentation은 한편 dynamically allocated memory에 대해 효율적인 관리 방법을 제공하기도 한다.
OS가 이전에 사용된 메모리 영역를 재사용하려고 한다면, 우선 해당 영역을 zero out 해야 한다.
그렇지 않으면 해당 영역에 저장되어 있던 중요한 정보들이 다른 프로세스가 해당 영역에 접근함으로써 유출 될 수 있기 때문이다.
그럼 zeroing을 어떻게 해야할까?
사실 문제가 되는 경우는 stack이나 heap 같이 확장 가능 영역이 확장할 때이다.
애초에 프로세스가 할당 될 때 할당 영역 자체는 초기화가 되므로, 기존 영역을 벗어나 확장을 시도하는 경우만 신경쓰면 되는 것이다.
그런데 문제는 얼마만큼 확장할건지를 모르기 때문에, 얼마만큼 zeroing을 해야하는지 모른다는 것이다.
Segementation은 이 문제에 zero on reference라는 놀라운 해답을 제공한다.
Zero on reference는 말 그대로 reference가 일어났을 때에만 zeroing 한다는 의미이다.
구체적인 동작은 이렇다.
우선 확장 가능 영역을 초기화 할 때 first few kilobytes만 zeroing 한다.
이후 확장 가능 영역이 확장이 되어야 할 때, 다시 말해 해당 영역에 대해 seg fault가 일어났을 때 확장해야 하는 영역만큼만 zeroing 한다.
이렇게 하면 zeroing overhead를 매우 줄일 수 있다.
Paging
Segmentation의 문제는 segment들이 너무 사이즈가 다양하다는 것이었다.
그러면 아예 고정된 사이즈로 자르면 안될까?
이 아이디어가 바로 paging이다.
Paging의 핵심은 memory를 fixed size unit으로 잘라서 관리하는 것이다.
이때 단위를 흔히 virtual memory에서는 page, physical memory에서는 page frame(or frame)이라고 부른다.
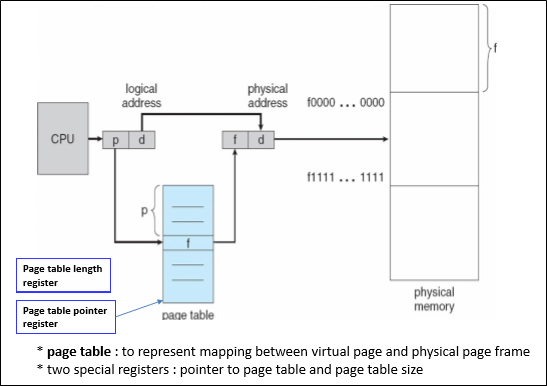
Address translation은 page table을 통해 이뤄진다.
구체적인 방법은 이렇다.
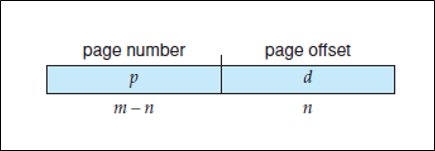
우선 virtual address를 p (page number)와 d (Offset)으로 자른다.
그 다음 p로 page table을 참조해서 PPN(Physical page number) 혹은 disk address를 얻어와 offset이랑 이어붙여 physical address를 구한다.
이때 잘못된 접근을 피하기 위해 page table size register가 필요하다. 만약 접근이 size를 넘는 접근이라면 exception이 발생한다.
Paging의 장단점에는 어떤 것이 있을까?
- 장점
- Segmentation의 문제점인 Complex memory management를 효과적으로 해결함
- Simple free-space allocation
Paging을 사용하면 physical memory를 bitmap(ex: 110101)으로 표시할 수 있기 때문에 free space를 매우 간편하게 찾을 수 있다.
- Easy to share
page table entry가 같은 physical page frame을 가리키게 하면 된다.
- Core map
Records information about each physical page frame such as which page table entries point to it
한편 Sharing을 구현하기 위해선 core map이 필수적으로 필요하다.
어떤 page를 Invalidate 또는 eviction을 할 때 이를 sharing 하고 있는 process들에 이를 고지해야 하기 때문이다.
- Core map
- Simple free-space allocation
- Segmentation의 문제점인 Complex memory management를 효과적으로 해결함
- 단점
- Page size problem
- If page size small?
Page table becomes too big
- If page size big?
Internal fragmentation
- If page size small?
- Page size problem
Paging and Segmentation On Additional Features
우리가 Segmentation에서 알아본 여러 additional features는 paging에도 동일하게 성립한다.
Copy-On-Write는 segment 단위가 아닌 page 단위로 수행하면 된다.
Zero on reference는 Segment table이 아닌 page table entry에 invalid를 표시하며, 확장할 때 page 단위로 zeroing 한다.
Paging은 또한 단순히 Segmentation과 동일한 기능을 지원하는 것을 넘어 fill on demand라는 기능을 추가로 제공한다.
Fill on demand는 프로그램의 data와 code를 전부 메모리에 올리지 않고도 실행할 수 있게 하는 기능을 말한다.
핵심은 page table entry를 전부 invalidate하여, 필요할 때 즉 access 할 때에 비로소 메모리에 올리도록 하는 것이다.
구체적인 동작 과정은 다음과 같다.
- Set all page table entries to invalid
- When a page is referenced for first time, OS kernel trap
- Trap handler in OS kernel brings page in from disk
- Resume execution
- Remaining pages can be transferred in the background while program is running
이 기능의 구체적인 구현 방법은 다음 포스트의 Demand Paging에서 알아볼 것이다.
Multilevel Translation
실제로 쓰이는 많은 OS들은 단순하게 paging 또는 segmantation만을 사용하진 않는다.
일반적으로 이들을 혼합한 형태인 tree-based address translation을 사용한다.
Tree-based address translation이란 단계별로 translation을 하는 것을 말한다.
예를 들어 1단계는 segmentation, 2단계는 paging 이런 식이다.
많은 방법이 있겠지만, 대부분의 OS는 paging을 lowest level로 채택하고 있다.
그 이유는 다음과 같다.
- Efficient memory allocation
By allocating physical memory in fixed-size page frames, management of free space can use a simple bitmap
- Efficient disk transfers
Hardware disks are partitioned into fixed-sized regions called sectors; disk sectors must be read or written in their entirety.By making the page size a multiple of the disk sector, we simplify transfers to and from memory, for loading programs into memory, reading and writing files, and in using the disk to simulate a larger memory than is physically present on the machine.
- Efficient lookup
Use of TLB, Paging allows the lookup tables to be more compact
- Efficient reverse lookup
Using fixed-sized page frames also makes it easy to implement the core map
- Variable granularity protection and sharing
Typically, every table entry at every level of the tree will have its own access permissions, enabling both coarse-grained and fine-grained sharing, down to the level of the individual page frame.
곧, 우리가 알아볼 것은 어떻게 page table까지 도달하는가? 에 관한 것이다.
Paged Segmentation
가장 간단한 two level tree scheme을 알아보자.
Paged segemntation은 segementation (1st level) - paging (2nd level)로 이루어진다.
Segementation level은 segement table에 의해 번역된다.
Segement table entry는 아래의 정보를 포함한다.
- Pointer to page table
- Page table length (number of pages in segment)
- Access permissions
Paging level은 page table에 의해 번역된다.
Page table entry는 아래의 정보를 포함한다
- Page frame
- Access permissions
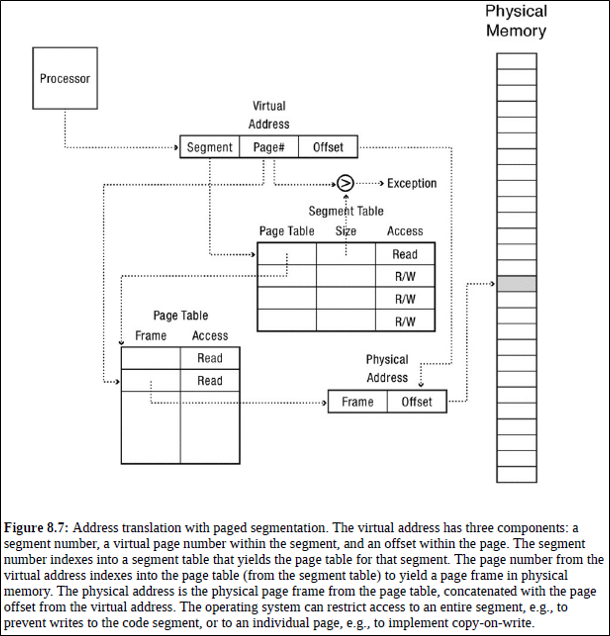
Paged segemntation은 address를 segemnt / page / offset 으로 나눈다.
주소 번역의 첫 단계는 segment part로 seg table을 참조하여 page table의 주소를 얻어오는 것이다.
이때, page part와 bound를 비교하여 해당 segement를 넘어가는 page를 참조하는지 확인해야 한다.
두 번째 단계는 page part로 첫 번째에서 얻어온 page table를 참조하여 PA를 얻어오는 것이다.
PA를 얻어왔다면, offset part를 붙여서 주소 번역을 끝낸다.
Multilevel Paging
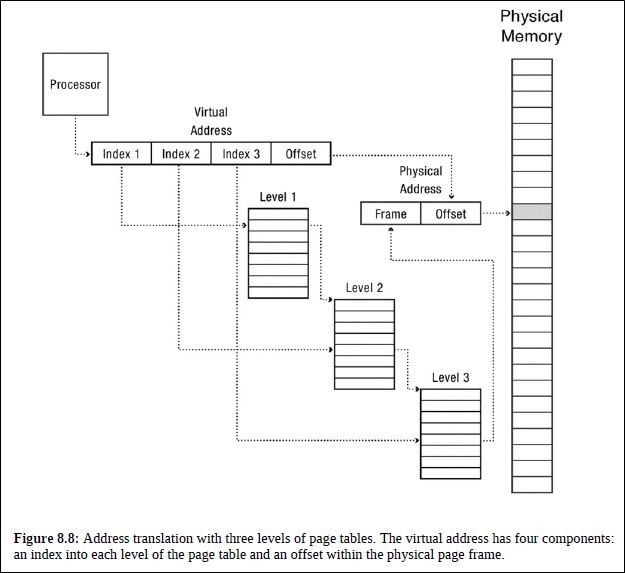
Paged segemntation과 비슷한 접근법은 multiple levels of page tables을 쓰는 것이다.
큰 page를 작은 page 단위로 자르고, 자른 것을 또 더 작은 page로 자른다는 느낌이다.
Lowest level page table은 PA를 갖고 있고, higher level page table은 lower level page table의 주소를 갖고 있다.
Multilevel Paging의 큰 장점 중 하나는 page table을 효과적으로 저장할 수 있다는 점이다.
아키 때 자세하게 배우겠지만, page table은 지나치게 크기 때문에 disk에 저장해야만 한다.
근데 그렇게 되면 접근 속도가 매우 느려지므로 translation 또한 매우 느려지게 된다.
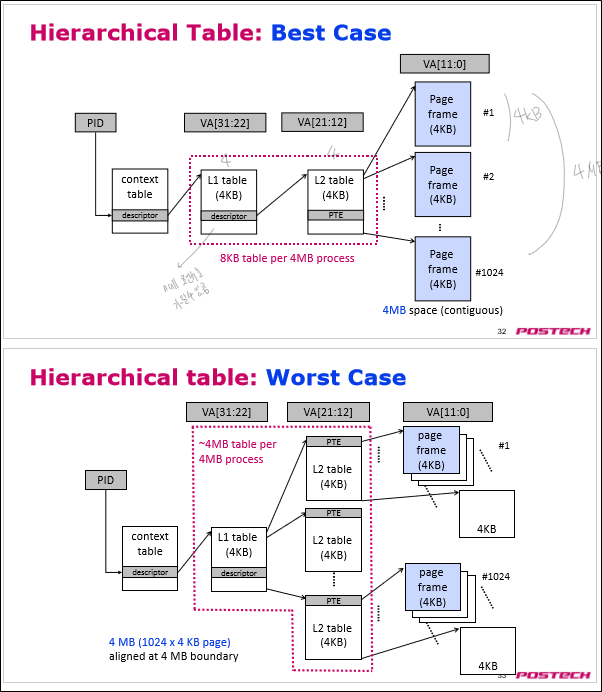
Multilevel Paging을 사용하면 page table tree 가지치기를 통해 저장해야 하는 page table의 수를 크게 줄일 수 있다.
위 두 케이스가 극단적인 형태를 잘 보여주고 있다.
x86 Multilevel Paged Segmentation
위 두 접근을 합쳐서 나온 것이 Multilevel Paged Segmentation이다.
Multilevel Paged Segmentation의 핵심은 segmantation를 최상위로 두고, 각 segement가 multi-level page table에 의해 관리되게 하는 것이다.
32bit case에 대해서만 설명하겠다.
x86은 per-process Global Descriptor Table (GDT)를 유지한다.
GDT는 segment table과 거의 동일한 의미라고 받아들이면 된다. (참고로 GDT로의 주소는 Global Descriptor Table Register(GDTR)에 저장되어 있다)
한편 GDT의 entry는 아래의 정보를 포함하고 있다.
- Pointer to (multi-level) page table for each segement
- Segement length
- Segement Access permission
Encoding efficiency를 위해, segement index는 보통 implicit 하게 번역된다.
예를 들어 x86 stack instruction such as push and pop 은 stack segment로의 접근으로 간주되고, branch instruction은 code segment로의 접근으로 간주된다.
물론 segment index를 explicit 하게 나타낼 수도 있다.
여기서 질문.
page table은 몇 레벨로 나누어야 할까?
일반적으로 한 page table이 한 page에 딱 맞게 들어갈 수 있도록 자르는 편이다.
Page size가 4KB라고 해보자.
Page size를 표현하는데 12 bit 가 필요하다.
그러면 32-bit에서 12 bit를 소모하고, 20 bit가 남았다.
이때, page table entry의 size가 4byte라고 하자.
page table이 4KB여야 하므로, page table entry의 수는 2^10 개여야 한다.
따라서 각 page table은 10-bit를 사용하고, 상위 20-bit는 10 / 10 으로 잘려서 2-level page table이 된다.
64-bit x86은 보통 4-level page table을 사용한다고 한다.
Portability
우리는 이제까지 굉장히 다양한 translation mechanisms에 대해서 알아보았다.
다양하다는 건 선택지가 많다는 장점도 있지만, 그만큼 OS designer에게 있어서 큰 스트레스가 된다.
OS는 수많은 processor architectures들에 대한 호환성을 갖춰야 하기 때문이다.
주로 OS는 아래의 정보들을 가지고 메모리 및 주소 번역 호환성을 구현한다.
- List of memory object
Memory objects are logical segments. Whether or not the underlying hardware is segmented, the kernel memory manager needs to keep track of which memory regions represent which underlying data, such as program code, library code, shared data between two or more processes, a copy-on-write region, or a memory-mapped file
- Virtual to physical translation
On an exception, and during system call parameter copying, the kernel needs to be able to translate from a process’s virtual addresses to its physical locations. While the kernel could use the hardware page tables for this, the kernel also needs to keep track of whether an invalid page is truly invalid, or simply not loaded yet (in the case of fillon-reference) or if a read-only page is truly read-only or just simulating a data breakpoint or a copy-on-write page.
- Physical to virtual translation
We referred to this above as the core map. The operating system needs to keep track of the processes that map to a specific physical memory location, to ensure that when the kernel updates a page’s status, it can also updated every page table entry that refers to that physical page.
아마 pintos project 3을 하고나면 이게 뭔 소린지 바로 와닿을 것이다.
Inverted Page Table
위 셋 중 가장 흥미로운 것은 Virtual to physical translation 이다.
Software page table을 구현함에 있어서 우리가 위에서 배운 segmentation이나 muli-level paging을 사용할 수도 있다.
그러나 이미 알아봤듯 위 구현들은 너무 큰 page table을 요구한다.
만약 bit가 늘어난다면, 그 크기가 지수적으로 늘어나기도 하니 확장성에 있어서 썩 좋다고 하긴 어렵다.
이걸 어떻게 개선해야 할까?
가만히 생각해보면, 어차피 쓰이는 건 physical memory 인데, 굳이 physical memory 보다 큰 table을 유지할 필요가 있냐는 생각이 든다.
이 아이디어를 이용해서 만든 것이 Inverted Page Table 이다.
Inverted Page Table은 physical memory와 같은 크기를 가지며, 각 page frame과 대응하는 오로지 하나의 entry만 가진다.
이때 각 entry는 아래의 정보를 포함하고 있다
- Virtual address of the page stored in that real memory location,
- Process that owns the page
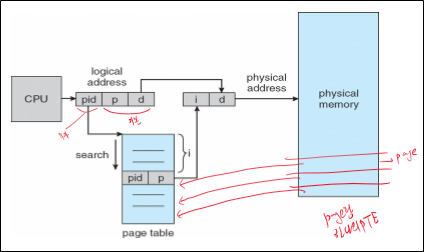
Inverted Page Table은 주소를 Page Number / Offset 으로 자르고, PID를 추가로 얻어온다.
그리고 나서 전체 i-page table을 조사하며 PID / Page Number 가 일치하는 entry를 찾는다.
Inverted Page Table의 entry는 같은 위치에서의 physical memory의 page와 대응하므로, 찾은 entry의 index i 가 곧 frame number가 된다.
이 방법의 장점이라 함은 말했듯 page table의 사이즈를 획기적으로 줄일 수 있다는 점이다.
그러나 번역을 위해 항상 전체 table을 탐색해야 하므로, 번역 속도가 꽤 느려진다는 단점이 있다.
이를 해결하기 위한 주된 방법이 hash table을 사용하는 것이다. 그러나, hash table은 결국 번역을 위해 두 번의 메모리 접근이 일어나므로 이에 따른 성능 저하도 만만찮다는 단점이 있다.
또한 sharing을 구현하는 것도 꽤 까다롭다는 단점이 있다.
3. Efficient Address Translation
이번 챕터에서는 address translation의 logical behavior을 바꾸지 않고, 퍼포먼스를 향상시킬 수 있는 방법에 대해서 배울 것이다.
TLB
Address translation의 성능을 향상시키기 위한 가장 명백한 방법은 메모리 접근에 걸리는 시간을 줄이는 것이다.
메모리 접근의 성능을 올릴 수 있는 가장 직접적인 방법은 cache를 도입하는 것이다.
Translation lookaside buffer (TLB)는 recent address translation에 대한 정보를 갖고 있는 작은 하드웨어 테이블이다.
TLB의 각 entry는 아래의 정보들로 구성되어있다.
- Virtual page number
- Physical page frame number
- Access permission
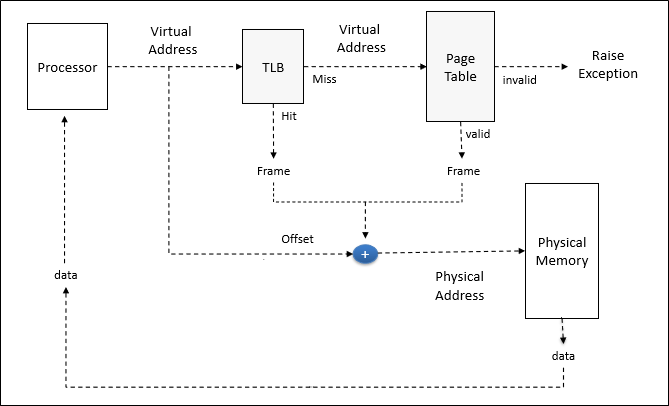
TLB를 이용한 address translation은 우선 TLB를 보고, 없는 경우에만 multi-level page table에의 접근을 시도한다. (이를 walk 라고 표현한다)
곧, address translation의 비용이 아래와 같이 줄어들게 된다.
Cost of TLB lookup + prob(TLB miss) * cost of page table lookup
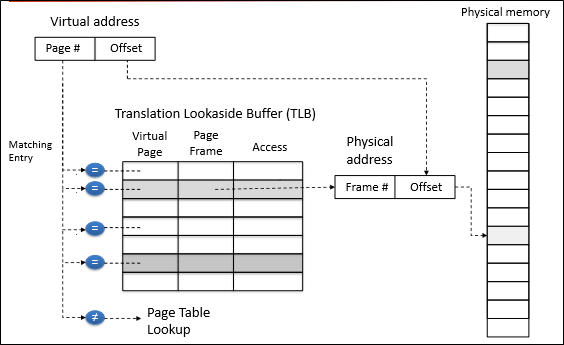
TLB는 구체적으로 위 그림과 같이 동작하게 된다.
주소를 page number / offset으로 자르고, page number로 TLB를 검색한다.
TLB hit라면 page frame number를 뽑아내 번역을 완료한다.
TLB miss라면 page table를 가지고 full address translation을 수행한다.
Translation이 끝나면 해당 translation을 TLB에 등록하게 된다.
만약 TLB에 빈 entry가 없다면 Cache eviction이 일어나야 한다.
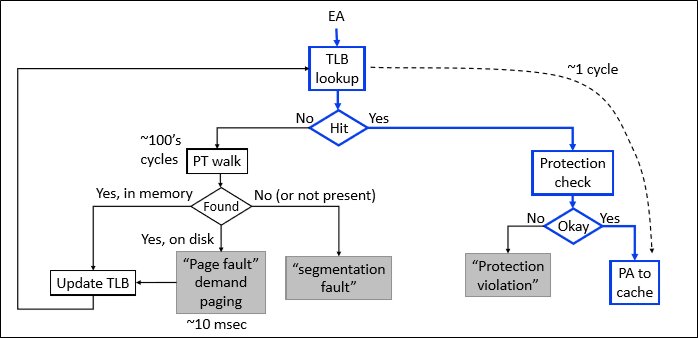
전체적인 흐름은 위와 같다.
한편 TLB는 Page table에 비해 상당히 빨라야만 한다.
그래서 주로 on-chip static memory로 구현되어 CPU 옆에 위치한다.
요즘 들어서는 성능 향상을 위해 muli-level TLB를 도입하고 있다고 한다.
또 한편으로 cache 검색을 빠르게 하기 위해 address comparator의 수가 작아야 한다.
따라서 TLB는 set associative로 구현되어야 한다.
SW Loaded TLB
여기서 질문.
TLB miss가 났을 때 굳이 hardware multi-level page table lookup을 해야할까?
이 아이디어가 SW Loaded TLB이다.
SW Loaded TLB에서는 TLB miss가 났을 때, HW address translation을 하는 대신 OS kernel로 trap을 한다.
이 Trap handler에서 kernel은 address lookup을 하고, TLB에 새로운 translation을 load 한다.
이 방법을 사용하게 되면 OS의 디자인의 자율성이 매우 커진다.
HW에 맞출 필요 없이, OS가 편한대로 page table을 디자인 할 수 있고, 주소 번역도 TLB load도 원하는 대로 제어할 수 있다.
그러나 Trapping을 하는 것 자체가 꽤 많은 사이클을 소모하기 때문에 성능에 있어서 꽤 손해가 생긴다는 단점이 있다.
Virtually Addressed Cache
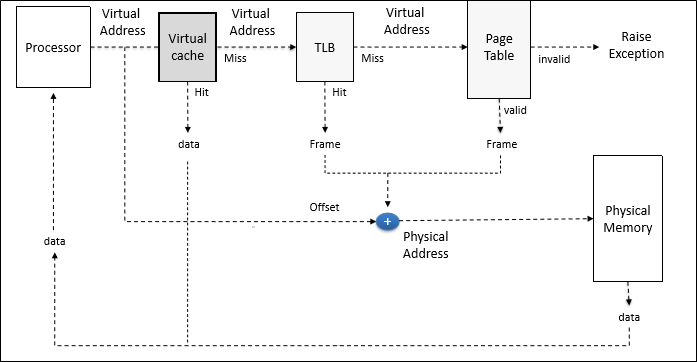
Cache를 이용해서 성능을 증가시키는 또다른 방법은 Virtually Addressed Cache를 도입하는 것이다.
Virtually Addressed Cache란 physicall address가 아닌 virtual address로 indexing을 한 cache를 의미한다.
이 cache를 이용하면 VA to PA의 번역 과정을 생략하고 곧바로 데이터를 얻을 수 있기 때문에 성능에 있어서 아주 큰 향상을 볼 수 있다.
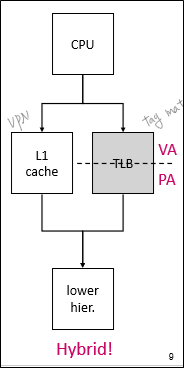
실전에서는 위와 같이 VA cache의 접근과 주소 번역을 동시에 일어나게 해 성능을 높이는 방법을 사용한다.
Aliasing
그러나 Virtually Addressed Cache는 aliasing 이라는 골때리는 문제를 낳는다.
Aliasing이란 서로 다른 VAs가 같은 PA를 가리키는 상황을 말한다.
Aliasing이 생기면 한 cache copy가 다른 cache copy의 update를 반영하지 못하는 문제가 발생한다.
이를 막는 가장 간단한 방법은 같은 PA를 가리키는 cached copy를 동시에 업데이트하는 것이다.
구체적인 동작은 아래와 같다.
-
위에서 봤던 hybird architecture를 채택하여, VA cache와 TLB 번역이 동시에 일어나게 한다.
-
TLB에서 얻은 PA를 가지고, VA cache를 검색하여 해당 PA를 가리키는 다른 entries가 존재한다면, 이 entries를 업데이트 또는 invalidate 한다.
Superpages

TLB의 hit rate를 올리는 방법 중 하나는 superpage를 사용하는 것이다.
Superpage란 set of contiguous pages in physical memory that map a contiguous region of virtual memory를 말한다.
곧, 한 TLB entry가 cover하는 영역을 늘려서 hit rate를 늘리는 방식인 것이다.
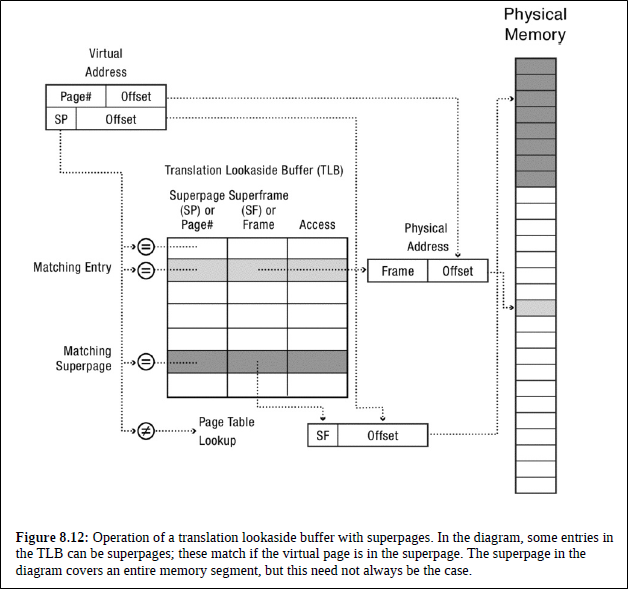
구현의 핵심은 TLB가 Superpage 또는 Page를 번역할 수 있도록 하는 것이다.
만약 해당 page가 superpage라면 SP / offset으로 번역하고, 그렇지 않다면 Page Num / Offset으로 번역한다.
Superpage를 설명할 수 있는 가장 좋은 예시는 computer display이다.
화면을 그리기 위해선 processor는 화면의 모든 pixel의 값을 건드려야 한다.
근데 알다시피 pixel의 수는 정말 엄청나게 많다.
그런데 그걸 기존의 TLB 구현으로 시도한다면 아마 계속해서 cache eviction이 일어나야만 할 것이다.
만약 Superpage를 사용하면 whole pixel frame을 한 entry에 mapping 시키면 되니까 매우 효율적으로 화면을 표시할 수 있다.
TLB consistency
Cache를 도입한다면 항상 original data와 cache data 간의 consistency를 어떻게 보장해야 할지 심각히 고민해야 한다.
TLB도 마찬가지이다.
TLB에서 고려해야 하는 isssues는 다음과 같다.
-
Process context switch
Context switch가 일어나게 되면 이전 process의 정보를 담고 있는 TLB는 더 이상 유효하지 않다.
TLB consistency를 유지하기 위해선 어떻게 해야할까?
가장 간단한 방법은 그냥 TLB를 discard(flush)하는 것이다.
그러나 이는 너무 많은 overhead가 발생한다.
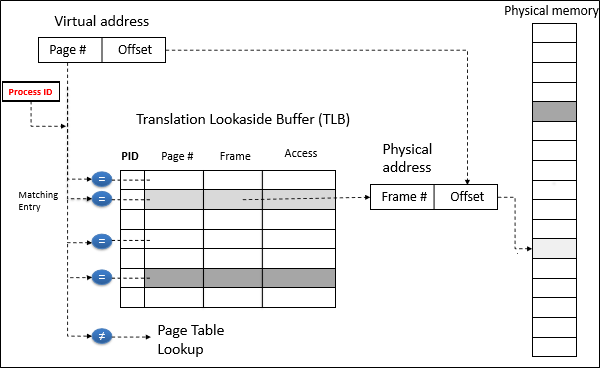
그 대신, TLB의 entry를 재사용하는 방법-tagged TLB-이 좀 더 효율적이다.
Tagged TLB의 핵심은 해당 translation을 소유했던 Process의 id를 저장하는 것이다.
VA 뿐만 아니라 PID 도 조사하여 TLB hit를 판단하는 것이다.
이 구현대로라면 context switch가 일어나더라도 아무것도 바꿀 필요가 없기 때문에 추가 동작도 없고, TLB entry도 재사용 할 수 있다는 장점이 있다.
-
TLB shootdown
Multiprocessor 환경을 생각해보자. 각 processor는 각자의 TLB를 가질 것이다.
이는 서로 다른 TLB가 같은 주소에 대한 entry를 가질 수 있음을 시사한다.
이렇게 되면 page table entry가 변경될 때마다 해당 주소에 대한 entry를 갖고 있는 모든 TLB가 해당 entry를 버려야 한다.
이때 해당 TLB를 소유하고 있는 processor 만이 해당 TLB를 수정할 수 있고, 또한 OS는 TLB가 어떤 page를 가지고 있는지 모르기 때문에 OS는 모든 processor에게 entry를 지우라는 interrupt를 날려야만 한다.
그리고 이 모든 processor가 무사히 요청을 완료했을 때에 비로소 동작이 끝이 난다.
이 heavyweight operation을 TLB shootdown이라고 한다.

예를 들어, processor 1이 page 0x53을 read-only로 바꾸었다고 해보자.
OS는 어떤 TLB가 page 0x53을 소유했는지 모르므로, 다른 모든 processor(2, 3)에게 old translation을 지우라는 interprocessor interrupt를 날린다.
이후 두 processor가 무사히 요청을 처리하고 나면, processor 1이 restart 한다.