[OS] Concurrency and Threads (1)
이 글은 포스텍 박찬익 교수님의 CSED312 운영체제 수업의 강의 내용과 자료를 기반으로 하고 있습니다.
OS 3주차 강의 요약이다.
Concurrency and Threads ppt 전체 내용을 다룬다!
1. Thread란?
1. Why we need thread?
어플리케이션은 기본적으로 한 번에 많은 것을 처리할 줄 알아야 한다.
Zoom을 예로 들어보면, 채팅 입출력, 영상 스트리밍, 대기열 등 수많은 기능들이 한꺼번에 돌아가고 있다.
이러한 Concurrency를 지원하기 위해서는 여러 개의 process를 만드는 것이 필수적이다.
그런데 이전 포스트에서도 언급했듯이, process를 생성하는 것은 꽤나 비용이 크다.
설상가상으로 program을 처음 실행할 때 process를 한 번에 다 생성하는게 아니라, 그때그때 상황에 맞추어 생성하기 때문에 performance 하락은 더욱 심해진다.
이 문제는 근본적으로 고비용의 process creation에 의한 것이다.
그러면 굳이 process 전체를 생성해야만 할까? 기능을 수행하는 부분만 잘라서 생성하면 안되나?
바로 이것이 Thread의 개념이다.
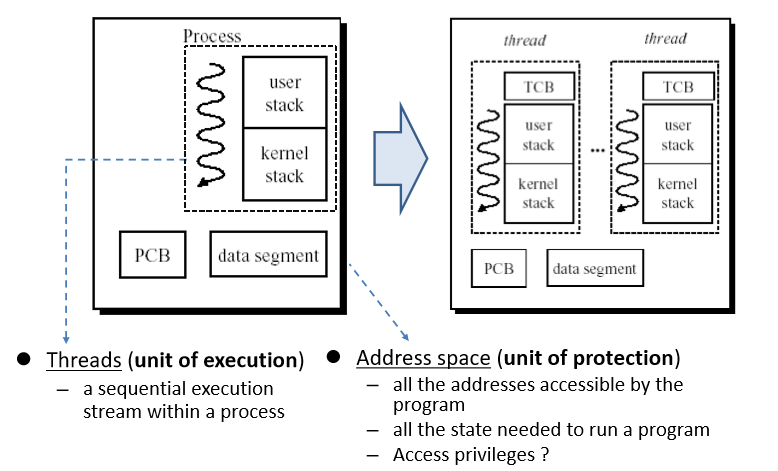
핵심은 process를 thread와 address space 두 개의 요소로 나누는 것이다.
실행에 있어서 독립적이어야 할 register, stack 등만 각각 소유하고, 나머지 heap, code, data 등은 공유하는 것이다.
그러면 구체적으로 thread가 process에 비해 어떤 이점을 가질까?
우선 당연히 creation 비용이 대폭 낮아진다.
또한 바꿔야 하는 것이 적으므로 context switch도 간단해진다.
마지막으로 address space를 공유하므로, 메모리 공유가 아주 쉬워진다.
실제로 측정해보면 process가 thread에 비해 creation은 30배 정도, context switch는 5배 정도 느리다고 한다.
2. Thread Abstraction
Thread가 unit of execution이라는 말은 thread 하나당 하나의 CPU를 점유해야 한다는 얘기이다.
그럼 multi-threaded 프로그램이 thread 수보다 적은 CPU를 가진 컴퓨터에서 돌아갈 수 있을까?
신기하게도 가능하다. 어떻게 이게 가능할까?
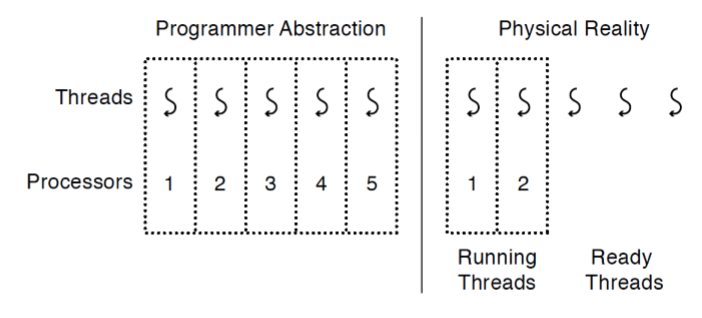
일종의 트릭이다.
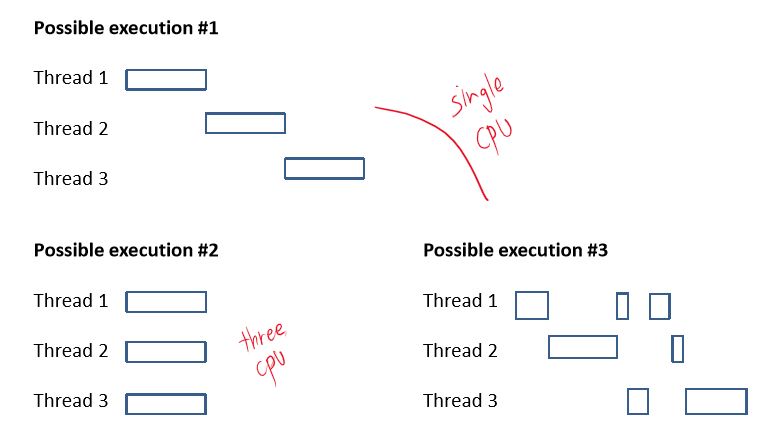
CPU는 위 그림처럼 thread들을 교체하면서 실행하는데(context switch), thread 입장에서는 자신이 교체된 것을 모르기 때문에 항상 자기가 CPU를 소유하고 있다고 착각한다.
이 착각은 프로그래머에게도 적용된다.

예를 들어, 이 코드를 짤 때 우리는 context switch를 생각하지 않고 짜도 된다.

왜냐하면 이렇게 context switch가 일어나더라도 결과적으로는 마치 일어나지 않은 것처럼 동작하기 때문이다.
이게 일종의 abstraction(추상화)이다.
Thread가 unit of execution이라는 것만 제공하고, variable speed로 동작하며 중간에 switching이 일어나기도 한다는 세부사항을 숨긴 것이다.
만약 abstraction이 제대로 되어있지 않으면 세부사항을 일일이 고려해야 하므로 상당히 골이 아플 것이다.
3. Thread Data Structure
Abstraction을 적용하기 위해선 어떻게 thread를 구현해야 할까?

CPU는 unit of execution 책임을 수행하는 객체는 모두 thread로 인식할 것이고, 그 객체의 세부사항은 state로 표현된다.
이 말은 state란 각 thread가 고유하게 가지는 정보 내지는 thread들을 구분짓는 문맥적 요소가 된다는 의미이다.
그리고 이 state가 바로 TCB, thread control block이다.
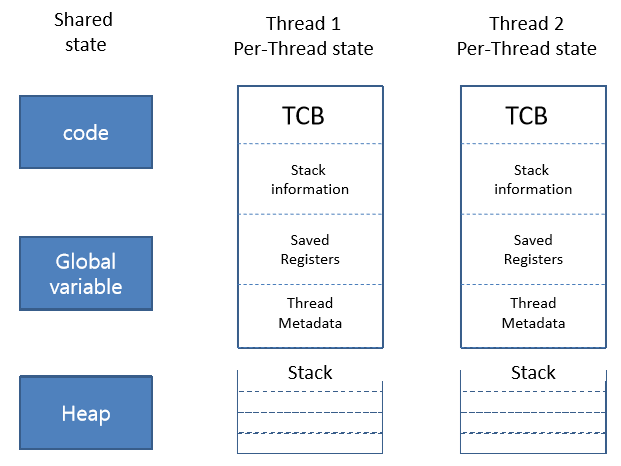
TCB는 stack, register, metadata로 이루어져있다.
이때 metatdata란 thread를 관리하기 위한 정보들을 의미한다.
예를 들어 thread ID, scheduling priority, status 등이 있다.
4. Thread Lifecycle
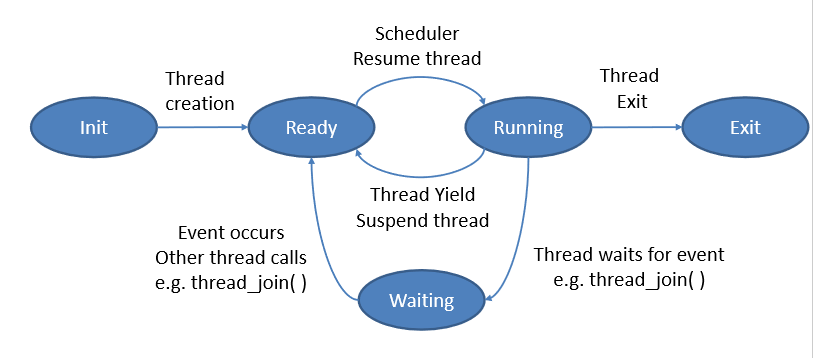
Metatdata에서 말하는 status란 thread lifecycle을 의미한다.
2. Implementing Thread
이제 자료구조도 다 알아봤으니, 구현해볼 차례이다.
여기서 중요한 점은 우리는 kernel thread를 구현하고자 하는 것이다.
User thread가 아니다!
왜냐하면 thread를 생성 및 관리하는 건 privileged operation이기 때문이다.
Multi-threaded user process를 만드는 방법은 이후 3. Multi-threaded user process에서 소개한다.
1. Thread Operations
Thread 객체는 다음 4가지 기능을 제공해야만 한다.
-
- thread_create(thread, func, args)
- Create a new thread to run func(args)
-
- thread_yield()
- Relinguish(양도하다) processor voluntarily
-
- thread_join(thread)
- In parent, wait for the forked thread to exit, then return
-
- thread_exit(exit_code)
- Quit thread and clean up. Wake up joiner if any, send exit_code to the joiner
우리가 알아볼 것은 thread_create()와 thread_yield()이다.
2. thread_create()
우선 thread_create()부터 알아보자.
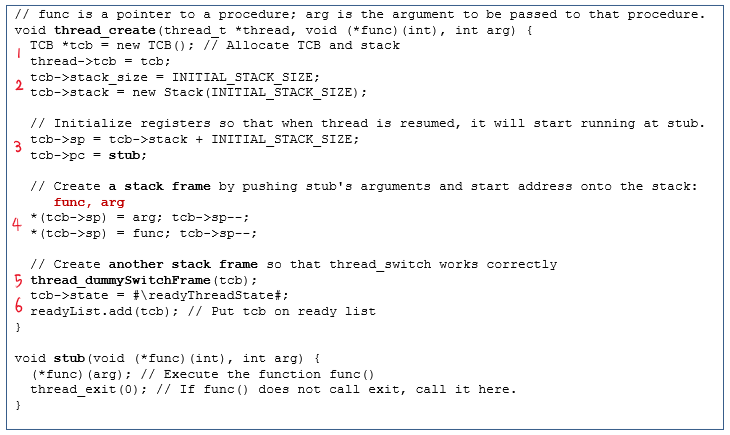
thread 생성은 다음의 과정으로 이루어진다.
- TCB 생성 및 할당
- Stack 할당
- Stub에서 시작할 수 있도록 program counter 조정하기
- Stack에 stub 인자들; func, arg 집어넣기
thread_switch를 위한 dummy stack frame 집어넣기- Thread를 ready list에 등록
아마 3, 4, 5번 과정을 이해하기 어려울 것이다.
5번은 나중에 다뤄보고, 3, 4번부터 이해해보자.
3, 4번의 핵심은 이렇다.
Thread가
func(arg)대신stub(func, arg)에서 시작하게 하자!
왜 이렇게 해야할까?
이는 thread가 종료될 때 exit()를 부르도록 강제하기 위해서이다.
func(arg)는 exit() 대신 return을 할 수도 있는데, 이 경우 thread 종료가 아닌 단순한 함수 종료로 취급된다.
이를 해결하기 위해, func(arg)가 return을 통해 종료하는 경우 stub(func,arg)가 이를 감지하고 exit()를 대신 호출하게 한 것이다.
3. thread_switch()
thread_yield()를 알아보기 전, thread context switch를 먼저 이해해야 한다.
우선 thread context switch에는 두 종류가 있다.
- Voluntary
thread_yield()thread_join()
- Involuntary
- Interrupt or exception
- Some other thread is higher priority

이 context switch는 기본적으로 아래의 과정을 통해 행해진다.
- Save registers on old stack
- Switch to new stack, new thread
- Restore registers from new stack
- Return
4. dummySwitchFrame()
thread_switch()는 register를 restore한 후 stack에서 return address를 읽어 해당 주소로 return 한다. (마프 때 배운 return의 원리를 잘 떠올려보자)
그런데 이 과정은 restore 하고자 하는 thread가 thread_switch()에 의해 suspend 된 경우에만 유효하다.
이 말인 즉슨, 생성된 직후의 thread는 thread_switch()를 한 적이 없기 때문에 stack에 register도, return address도 저장되어 있지 않아 thread_switch()가 불가능해진다는 것이다.

따라서, thread_create()를 한 이후에 dummy stack frame을 생성해서 마치 thread가 stub()에서 thread_switch()를 부른 것처럼 만드는 것이다.
5. thread_yield()
이제 thread_yield()를 알아볼 수 있다!
사실 굉장히 간단하다.
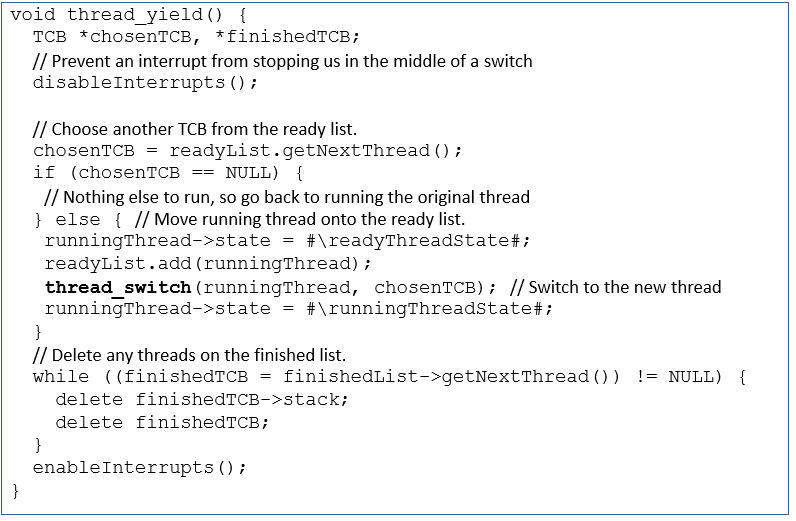
thread_yield()는 호출한 thread를 ready list에 집어넣고, 다음으로 실행할 thread와 context switch를 한다.
이때, interrupt로 인한 nested switching을 방지하기 위해 interrupt를 disable했다.
나머지 자잘한 코드들은 예외처리들이니, 한 번 읽어보면 이해가 갈 것이다.
그럼 여기서 문제!
Suspend 된 thread가 이후에 다시 실행될 때, 어디서 시작하게 될까?

정답은 thread_switch()이다!
따라서 우선 thread_switch()에서 return 한 후, thread_yield()에 의해 suspend된 경우라면 이를 거쳐서, 그렇지 않다면 곧바로 예전 코드로 돌아가게 된다.
또 한 가지 확인해야 할 점은 dummySwitchFrame에 의해 새로 생성된 thread가 마치 stub에서 thread_switch()를 부른 것 처럼 동작한다는 점이다.
6. Involuntary Thread Switch
그럼 비자발적으로 context switch가 일어나는 경우는 어떻게 될까?
세 단계를 거친다.
-
Save the state
Save the currently running thread’s registers so that the handler can run code without disrupting the interrupted thread.
-
Run the kernel’s handler
Run the kernel’s handler code to handle the interrupt or exception.
Since we are already in kernel mode, we do not need to change from user to kernel mode in this step.
-
Restore the state
Restore the next ready thread’s registers so that the thread can resume running where it left off.
구현법은 의외로 간단한데, interrupt handler가 끝날 때 thread_switch()를 부르면 된다.
그러면 interrupt handling이 끝날 때 다른 thread로 cpu를 넘기게 되고, 이후 원래 thread가 resume 하면 thread_swich()에서 return하여 이전 코드로 되돌아가게 된다.
한 가지 재밌는 점은 원래 thread의 state가 interrupt에 의해서 한 번, thread_switch()에 의해 다시 한 번, 총 두 번 store/restore 된다는 것이다.
3. Multi-threaded User Process
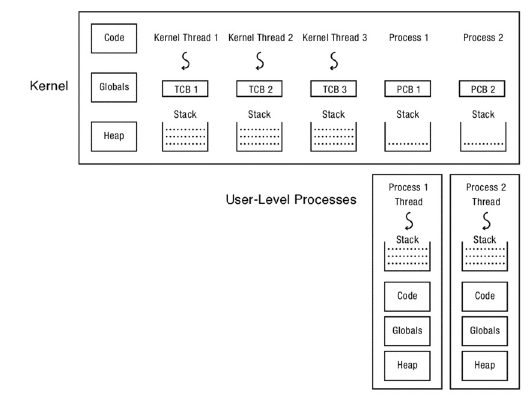
우리가 이제까지 배운 것은 multi-threaded kernel이다.
그럼 multi-threaded user process는 어떻게 구현해야 할까?
크게 3가지의 구현법이 있다.
1. Multi-Threaded Processes Using Kernel Threads
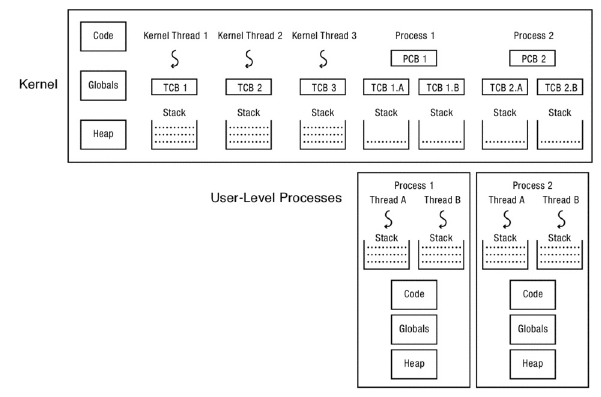
가장 간단한 방법으로, 위에서 설명한 kernel thread implementation을 사용해서 multi-threaded process를 구현할 수 있다.
구현의 핵심은 system call을 사용하는 것이다.
예시로 thread를 생성하는 과정을 알아보자.
우선 user library가 user-level stack을 할당한 다음 thread를 생성하라는 system call을 한다.
그러면 kernel은 TCB, interrupt stack을 할당하고 thread의 시작 지점을 user-level stack으로 조정 한 다음, thread를 ready list에 넣는다.
Thread join, yield, exit 모두 이렇게 system call을 이용해서 구현한다.
그러나 이 방법은 thread operation이 모두 system call이기 때문에 성능이 많이 나빠진다는 단점이 있다.
2. User-Level Threads Without Kernel Support
1번의 단점을 개선하기 위해 나온 방법이 아예 user-level thread를 구현하는 것이다.
구현의 핵심은 thread 기능을 제공해주는 thread library를 만드는 것이다.
마치 system call을 하듯 library로 function call을 하면 library가 thread를 생성 및 관리해준다!
이 방법의 장점은 thread에 대해 user-level process가 완벽한 제어를 할 수 있다는 것이다.
하지만 이렇게 구현한 user-level thread들은 OS에 의해 인식되지 않기 때문에 OS는 그냥 singe-threaded process로 간주해버려 system call 같은 interrupt가 발생했을 때 OS가 다른 user-level thread로의 전환을 하지 못한다는 단점이 있다.
3. User-Level Threads With Kernel Support
2번의 단점을 개선하기 위해 나온 방법이 kernel의 도움을 받는 user-level thread를 구현하는 것이다. 일종의 하이브리드 모델이라 할 수 있겠다.
많은 내용이 있지만, PPT에서는 scheduler activation만 소개하고 있다.
Scheduler activation의 핵심은 kernel에게서 user-level thread system에 영향을 끼치는 이벤트를 전달받는 user-level thread schedular를 만드는 것이다.
User-level thread schedular는 전달받은 이벤트에 맞추어 user-level thread를 직접 관리하는 역할을 수행한다.
참고로 이 이벤트 전달을 Upcall이라고 한다.
아마 조금 와닿지 않을 수도 있다. 예를 들어보자.
Kernel이 어떤 user thread의 I/O가 끝난 것을 감지하여, 이 thread를 WAITING 상태에서 READY로 바꾸려고 한다고 해보자.
이때 kernel은 이 이벤트를 user-level thread schedular에 전달해주고, 이벤트를 받은 schedular는 해당 thread를 직접 resume한다.
4. Threading Issues
Thread를 구현함에 있어서 몇 가지 이슈들이 있다.
-
Semantics of
fork()andexec()system callsMultithread 환경에서는
fork()와exec()의 구현이 상당히 골아파진다.생각해보자. Multithread 환경에서
fork()를 호출하면, 호출한 thread만 복제해야 할까 아니면 모든 thread를 복제해야할까?exec()도 마찬가지로, 호출한 thread만 덮어씌워야 할까 아니면 모든 thread에 덮어씌워야 할까?교과서에서는 나름의 방향을 제시해주고 있다.
fork()후 곧바로exec()를 한다면 호출한 thread에 대해서만 적용하고, 반대의 경우라면 모든 thread에 대해서 적용해라! -
Signal handling
Synchronous로 구현할 것인가 asynchronous로 구현할 것인가?
-
Thread cancellation
Thread cancellation이란 thread가 동작을 완료하기 전 강제로 종료시키는 걸 말한다.
예를 들자면, 크롬 브라우저가 열심히 로딩하고 있을 로딩을 중지시켜 로딩 동작을 수행하는 thread를 강제 종료하는 것이 있겠다.
그런데 이 강제종료를 즉각적으로 해야 할까 아니면 중단할 수 있는지 물어보고 해야 할까?
전자를 Asynchronous cancellation, 후자를 Deferred cancellation이라고 한다.
Asynchronous cancellation의 경우 구현이 쉽긴 하겠지만 만약 thread가 shared data에 업데이트를 하고 있는 상황이었다면 꽤나 큰 문제가 될 수 있다.
반대로 deferred cancellation은 thread가 종료될 수 있는지 물어보고 하기 때문에 data consistency를 지킬 수는 있지만 그만큼 구현해야 하는게 많고 좀 느리다.
-
Thread local storage(TLS)
Thread가 고유하게 가지는 데이터를 의미한다.
지역 변수와 헷갈릴 수 있는데 지역 변수는 접근 범위가 함수 내이고, TLS는 thread 전체이다.
일종의 static data라고 생각하면 된다.