[OS] Process Abstraction (2)
이 글은 포스텍 박찬익 교수님의 CSED312 운영체제 수업의 강의 내용과 자료를 기반으로 하고 있습니다.
OS 2주차 강의 두번째 요약이다.
하도 하는 일이 많다보니 조금씩 글 쓰는게 밀리고 있다.. ㅠㅠㅠ
OS는 ppt 순서랑 책 순서가 달라서 글 구조도 작성하는 것도 어렵고.. 내용도 어려워서 유독 손이 안가는 주제인 것 같다.
그래도 열심히 해야지…
1. Process management
이전 시간까지 process의 개념에 대해서 배웠으니, 이제 process의 동작에 대해서 배울 시간이다.
1. Process state transition
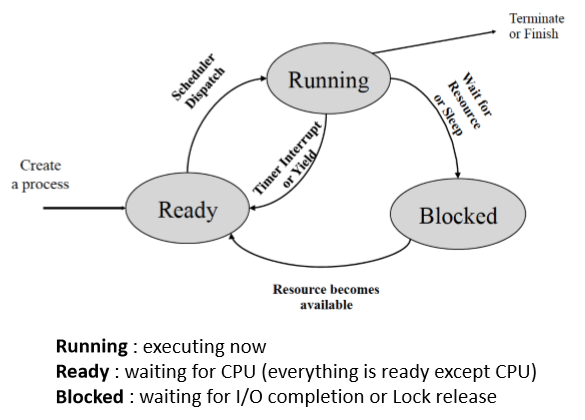
우선 process의 state에 대해서 정의하고 가자.
Process는 Ready, Running, Blocked 세 가지의 state를 가질 수 있다.
각 state가 의미하는 바는 상당히 명확하다.
기억해야 할 부분은 언제, 어떻게 state transition이 일어나는가 이다.
몇 가지 중요한 state transition을 정리해보았다.
- Ready → Running
- Short-term shedular에 의한 dispatch
- Running → Ready
- Interrupt (Involuntary)
- Yield (Voluntary)
- Running → Blocekd
- I/O or event wait
- Blocked → Ready
- I/O or event completion
참고로 state의 이름들은 중요하지 않다. OS별로 다르기도 하고.
실제로 어떤 교재는 blocked를 waiting이라고 표기하기도 한다.
그러니 이름에 집중하기 보다는 의미와 transition을 이해하도록 노력하자!
2. Process creation
Process를 사용하려면 일단 만들어야 한다.
기본적으로 process는 다른 process에 의해 생성된다.
이때 생성된 process를 child process, 생성한 process를 parent process라 부른다.
그러면, 최소한 한 개의 process가 기본적으로 제공되어야 process들을 생성할 수 있을 것이다.
이 기본적으로 제공되는 프로세스를 init 라고 부른다.
그럼 init는 모든 process의 조상이 될 것이고, 이를 바탕으로 전체 process 구조도를 그려보면
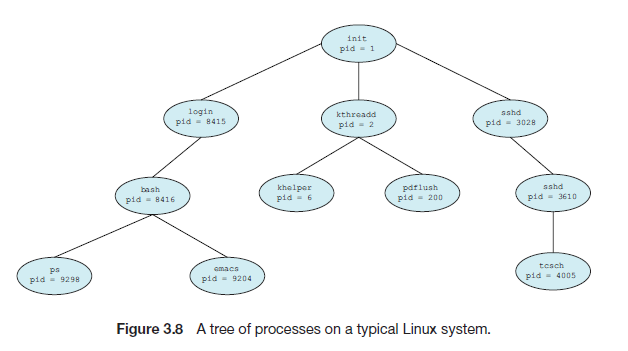
위와 같이 init를 root로 하는 tree 모양이 나올 것이다.
참고로 Process들은 생성 당시에 제공받은 고유한 아이디-pid-를 통해 식별된다.
이제 creation의 세부사항을 살펴보자.
우선 자원은 어떻게 할당받을 수 있을까?
- Obtain resource directly from the OS
- Share subset of the resources of the parent process
- Share all resources of the parent process
이렇게 세 가지 경우가 존재할 것이다.
그러면 생성 직후 동작은 어떻게 해야할까?
- concurrently execute
- parent waits, child executes
이렇게 두 가지 경우가 존재할 것이다.
그러면 address space(code, stack, data, …)는 어떻게 설정해야 할까?
- duplicate of the parent process
- load new program
이렇게 두 가지 경우가 존재할 것이다.
다행히도 우리는 이 많은 경우에 대해서 모두 다루지는 않고 UNIX에서 사용하는 fork()만 다룬다.
fork()는 parent process의 address space를 복사하여 child process를 생성하고, parent와 child 둘 다 실행시키는 함수이다.
fork()의 재밌는 점은 두 번 반환한다는 것이다.
Parent process에서는 생성된 child process의 pid를 반환하고, child process에서는 0을 반환한다.
pid = fork();
if(pid == 0)
printf("I'm child process!");
else
printf("pid of child process is : %d", pid);
그래서 위 코드처럼 fork의 반환값으로 if문을 돌려서 parent와 child를 구분하는 코드를 기본으로 사용한다.
참고로 parent와 child가 같은 위치에서 시작하는 것은 child가 PCB를 복사했기 때문에 instruction pointer의 위치가 같아서 그렇다.
그리고 fork()와 떼어놓을 수 없는 exec()라는 함수가 있다.
우리가 process를 생성하는 가장 큰 이유는 다른 프로그램을 실행시키기 위해서이다.
근데 fork()를 하면 parent와 같은 address space를 가지는 child가 생성되므로, child의 코드/데이터 등을 덮어씌워줄 필요가 있다.
바로 이 동작을 exec()가 수행한다.
pid = fork();
if(pid == 0)
exec(...);
else
printf("pid of child process is : %d", pid);
이런 식으로 말이다.
3. Process termination
생성을 했으면, 종료할 줄도 알아야 한다.
기본적으로 종료는 exit() 함수를 통해서 한다. 혹은 main()에서 return을 해도 된다.
그런데 한 가지 유의할 점은, process는 죽어서도 메모리를 소비하는 놈이라는 것이다.
왜냐하면 child는 자신의 exit status를 parent에게 전달해야 할 책임이 있기 때문에 parent가 받기 전까지는 이를 유지해두어야 하기 때문이다.
이렇게 죽어도 죽은게 아닌 process를 zombie process라고 한다.
그럼 어떻게 이 좀비를 죽일 수 있을까?
바로 wait()을 이용하면 된다.
wait()은 종료된 child process의 exit status를 가져와 인자로 주어진 포인터 변수에 넣어주는 역할을 한다.
만약 종료된 child가 있으면 곧바로 가져오겠지만, 그렇지 않다면 process를 child가 종료될 때까지 block 시킨다.
가장 좋은 예시는 shell이다.
Shell은 커맨드 라인으로 프로그램과 인자를 전달받아, 이를 child process에서 실행하는 역할을 한다.
이때, parent process는 생성 이외에 다른 역할을 하지 않으므로, 생성 후 곧바로 wait()을 부르면 된다.
char *prog, **args;
int child_pid, status;
while(readAndParseCmdLine(&prog, &args)){
child_pid = fork();
if (child_pid == 0){
exec(prog, args);
/* NOT Reached here!! */
}
else{
wait(&status);
return 0;
}
}
이런 식으로 말이다.
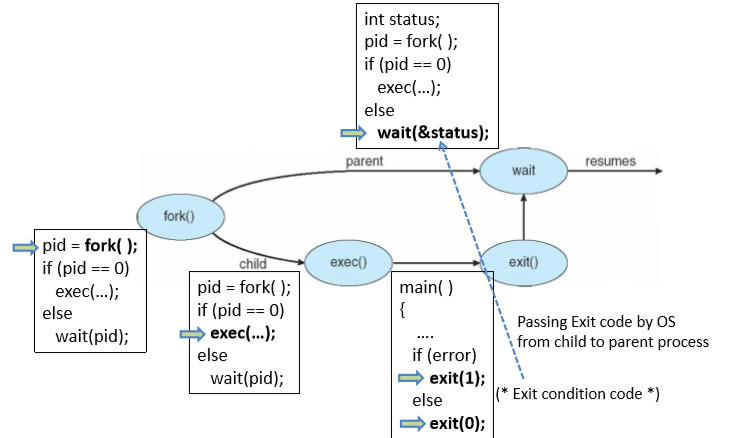
이해를 돕기 위해 다이어그램을 하나 첨부하였다.
그런데 만약 parent가 wait()을 부르지 않고 먼저 종료되어버리면 어떻게 될까?
죽일 방법이 없는, 진짜 좀비가 되어버린다.
이런 process를 orphan process라고 부른다.
이 경우 몇 가지 대응법이 존재한다.
리눅스의 경우 이런 프로세스들을 init로 입양시킨 다음, init에서 주기적으로 호출하는 wait()에 의해 죽게한다.
어떤 OS는 그냥 자동적으로 죽여버리기도 한다.
2. Process context switch
우리는 위에서 여러 process가 동시에 존재할 수 있음을 봤다.
근데 만약 CPU 개수가 process 개수보다 작다면, 어떻게 이 process들을 전부 실행할 수 있을까?
간단하다. CPU가 process들을 돌아가면서 실행해주면 된다!
이를 context switching 이라고 한다.
여기서 context란 PCB를 의미한다고 생각하면 된다.
곧, context switchig은 CPU가 실행하고 있는 PCB를 바꿔 끼우는 것이라 할 수 있다.
이때 바꿔 끼운다는 것은 구체적으로 우선 현재 PCB를 저장하고(state save), 실행할 PCB를 CPU에 로드(state restore)하는 것을 말한다.
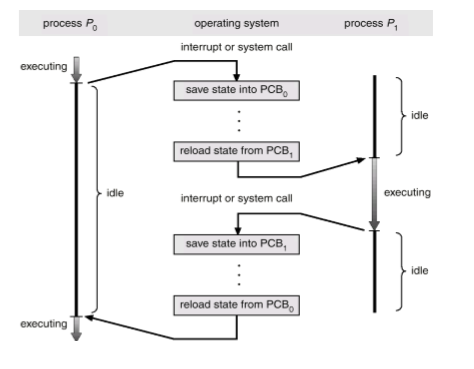
구체적인 구현법에 대해서 배우지는 않으니, 전체적인 흐름 정도만 기억해도 좋을 것 같다.
3. Process Schedulers
위에서 context switching을 한다고 했는데, 그럼 언제 어떤 process에 대해서 context swiching을 해야할까?
조금 더 나아가서, 언제 어떤 process를 disk에서 메모리로 올려야 할까? 반대로 언제 disk로 보내야 할까?
이런 process의 실행 관리를 통칭하여 process sheduling이라고 한다.
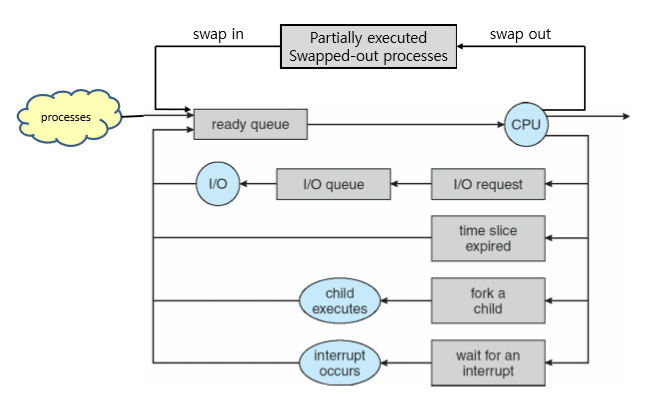
이 scheduling을 위해서는 특정 상태에 있는 process들을 저장하기 위한 자료구조들이 필요하다.
기본적으로 system 상에 있는 모든 process들은 job queue에 들어가있다.
이 중 ready 상태에 있는 process들은 ready queue에 들어가 있고,
block 상태에 있는 process들은 wait queue에 들어가 있으며,
특정 I/O request가 처리되길 기다리고 있는 process들은 I/O queue에 들어가 있다.
아래에서 설명한 schedular들은 이런 자료구조들을 활용하여 다양한 scheduling을 한다.
1. Long-term schedular
첫 번째로 알아볼 것은 Long-term schedular이다.
Long-term schedular는 mass-storage devide(disk)에 있는 process들을 메모리에 load하는 역할을 수행한다.
Process creation과 거의 동일한 의미라고 받아들이면 된다.
기본적으로 process creation은 자주 일어나진 않기에, long-term 이라고 이름 붙인 것이다.
Long-term schedular에서 추가적으로 알아야 하는 개념은 degree of multiprogramming이다.
Degree of multiprogramming이란 메모리에 상주하고 있는 프로세스의 수를 의미한다. 동시에 실행 가능한 프로세스의 수라고 생각하면 된다.
그럼 이 degree of multiprogramming과 Long-term schedular이 무슨 관계가 있는걸까?
Process를 메모리에 올리는 역할을 한다는 말은 degree of multiprogramming을 컨트롤한다는 말과 동일하기 때문에, 일종의 컨트롤러 역할을 한다고 보면 된다.
그럼 어떻게 해야 좋은 degree of multiprogramming을 얻을까?
간단하다. 좋은 degree of multiprogramming이란 process가 system을 떠나는 속도와 system에 들어오는 속도가 일치하는 상태를 말한다.
따라서, process가 system을 떠나는 때에만 schedular를 실행하면 된다.
그럼 가져올 process들을 어떻게 선택해야 최적의 성능을 낼까?
결론적으로, I/O-bound process와 CPU-bound process의 균형을 맞추면 된다.
I/O-bound process란 computation보다 I/O에 시간을 더 많이 쓰는 process를 의미하고,
CPU-bound process란 반대로 I/O보다 computation에 시간을 더 많이 쓰는 process를 의미한다.
그럼 왜 균형을 맞춰야 할까?
극단적인 케이스를 가정해보자.
만약 죄다 I/O-bound process라면 ready queue가 항상 비어 있을 것이고, 아래에서 배울 short-term shedular가 아무것도 안하고 탱자탱자 놀게 된다.
반대로 죄다 CPU-bound process라면 I/O waiting queue가 항상 비어있을 것이며, device들이 아무것도 안하고 놀게 된다.
곧, 균형을 맞춰야 하는 이유는 이 둘의 균형을 잘 맞춰야만 어느 한쪽이 놀지 않고 성실히 일을 수행해 좋은 성능을 뽑아낼 수 있기 때문이다.
2. Short-term schedular
두 번째로 알아볼 것은 Short-term schedular이다.
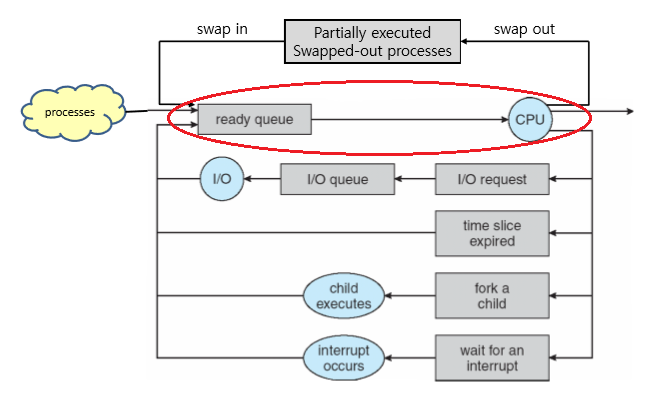
Short-term schedular는 ready queue에서 실행할 process를 선택해서 CPU에 allocate하는 schedular이다.
당연히 이런 switching은 상당히 자주 일어난다.
그리고 자주 일어나는 만큼 빨라야만 한다.
3. Mid-term schedular
마지막으로 알아볼 것은 Mid-term schedular이다.
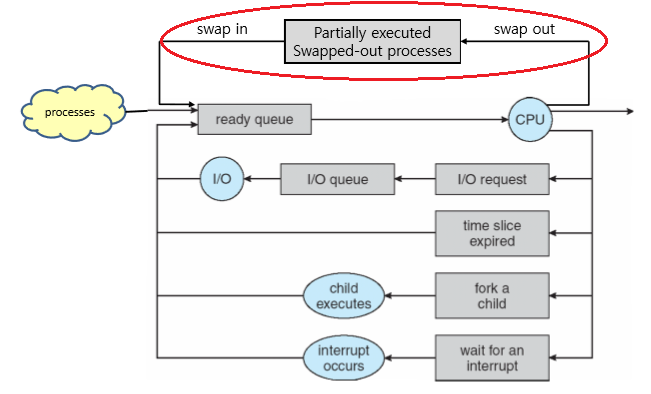
Mid-term schedular는 swapping을 수행하는 schedular이다.
Swapping이란 무엇일까?
간단히 말해서, process를 메모리에서 disk로 잠시 보냈다가, 이후에 이전 상태 그대로 disk에서 불러와서 다시 실행하는 것을 말한다.
이때 disk로 보내는 걸 swap out,
disk에서 불러오는 걸 swap in이라고 한다.
그럼 swapping을 왜 해야할까?
- I/O-bound와 CPU-bound의 균형을 맞추기 위해서
- requirement의 변화 등으로 메모리 사이즈가 변해 일부 process를 버리기 위해서
정도가 있겠다.
자세한 내용은 이 블로그를 참조하자. 양햄찌