[Algorithm] Dynamic Programming (1)
이 글은 포스텍 오은진 교수님의 CSED331 알고리즘 수업의 강의 내용과 자료를 기반으로 하고 있습니다.
원래 저번주에 글을 썼어야 했는데 망할놈의 핀토스 때문에 글이 늦어졌다.
딴건 다 쉬웠는데 multi-oom 때문에 하루를 썼다 하..
알고리즘은 사실 드랍하려고 했었다. 객관식 시험이 너무 충격적이어서.. 내가 이걸 기말에 또 칠 자신이 없었다.
근데 교수님이 채점 결과를 너무 늦게 주시는 바람에 드랍을 못했다.
서술형을 적당히 잘 봐서 결과적으로 A- 안정권에 진입한 것 같긴 한데.. 솔직히 1등 성적이 너무 높다 ㅡㅡ
기말까지 쳐서 점수차가 더 벌어지면 조질 각이다.
아.. 알고리즘 정말 힘들다.
Dynamic Programming 이란
이번 주차에 배워볼 것은 Dynamic Programming이다.
뭔가 동적으로 풀어야 하는건가..? 싶은데 정작 뜻은 dynamic과 별 관계가 없다.
Dynamic Programming이란 하나의 문제를 단 한 번만 풀도록 하는 알고리즘을 의미한다.
좀 더 구체적으로는 큰 문제를 작은 문제들로 나눠 입력 크기가 작은 부분 문제들을 해결한 후, 해당 부분 문제의 해를 활용해서 보다 큰 크기의 부분 문제를 해결하여 최종적으로 전체 문제를 해결하는 알고리즘이다.
사실 이해하고 이 말을 들으면 아~ 하는데 이해하기 전이면 이게 뭔 소린가… 싶을 것이다.
그러니 예제를 통해 알아보자!
Shortest Paths in DAGs
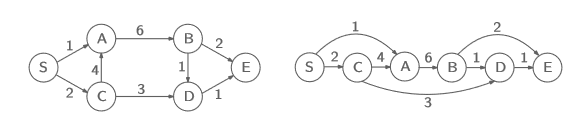
DAG에서의 shortest path는 어떻게 구해야 할까?
한 번 $D$까지의 shorest path를 구해보자.
$dist(D)=min\lbrace dist(B)+1,dist(C)+3\rbrace$
그럼 각각의 $dist$를 어떻게 구해야 할까?
재귀적으로 말고, 왼쪽부터 순서대로$(dist(S), dist(C), dist(A), \cdots ,dist(E))$ 풀어나가면 된다.
이를 알고리즘으로 표현하면 다음과 같다.

이렇게
- 문제를 쪼개고
- 크기가 작은 순서대로 subproblem을 정렬하고
- 더 작은 subproblem을 이용해서 더 큰 subproblem을 푸는
형태의 알고리즘을 dynamic programming이라고 한다.
어떻게 보면 분할정복과 비슷해 보이지만, 아주 큰 차이가 있다.
이에 대해선 우리 조교님 블로그를 참조하자. DP
여하튼, dynamic programming은 문제를 아래의 과정을 통해 풀이한다.
- Ordering: subproblem을 정의하고, subproblems의 순서를 정한다. (ex: $dist(S), dist(A),\cdots,dist(E)$)
- Relation: subproblem 간에 관계를 정한다. (ex: $dist(v)=min\lbrace dist(u)+l(u,v) \rbrace$)
- Algorithm: 1,2 로부터 알고리즘을 정의한다.
지금부터는 여러가지 예시를 통해 dynamic programming을 익혀볼 것이다.
다만 곧바로 답을 보지 말고 어떻게 풀까 생각해보길 바란다. DP는 감을 잡는게 매우 중요하다.
Longest Increasing Subsequences
Given a sequence of numbers, find an increasing subsequence of greatest length
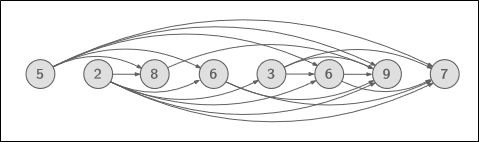
예시로 $5,2,8,6,3,6,9,7$ 이 주어졌다고 해보자.
이 문제를 dynammic progrmming으로 풀어보자.
-
Ordering:
-
주어진 seqeunce에 왼쪽부터 $1,2,\cdots,n$로 순서를 매긴다.
-
Subproblems: $j$로 끝나는 longest increasing subsequnece (LIS)
-
-
Relation:
-
$j$번째까지의 LIS는 $j$를 포함했을 때 증가를 유지할 수 있는 $j$ 이하의 subproblem들로 표현된다.
= Graph of all permissible transitions
-
-
Algorithm:
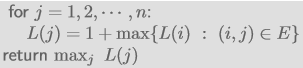
- Time compleixty:
- Number of subproblems: $n$
- Time complexity for each subproblem: $in-degree\;of\;j$
- Total $\sum_{j} in- degree(j)=O(\lvert E \rvert)=O(n^2)$
- Time compleixty:
Edit Distance
Edit Distance란 두 개의 문자열이 같아지기 위해 수행해야 하는 연산의 수를 의미한다.
유사도 검사 알고리즘에 종종 사용된다.
간단한 예시를 통해 edit distance를 이해해보자.

예를 들어, SNOWY와 SUNNY의 edit distance는 어떻게 될까?
우선 SNOWY와 SUNNY를 다양한 방법으로 비교할 수 있다. 위 그림은 수많은 방법 중 두 가지를 보여주고 있다.
이때, 이 특정한 alignment에서 문자가 다른 column의 개수를 그 aligment의 cost라고 한다.
따라서 edit distance란 best possible alignment의 cost를 의미하게 된다.
아마 이 문제에서는 edit distance가 3일 것이다.
이제 이 문제를 DP로 풀어보자.
-
Ordering:
-
주어진 두 string을 $x[1\cdots m], y[1\cdots n]$이라고 한다.
-
Subproblems: $E(i,j)$ = 두 prefix $x[1\cdots i], y[1\cdots j]$의 optimal edit distance
-
-
Relation:
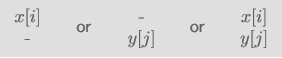
$E(i,j)$를 구하는 세 가지 경우가 존재한다.
- $E(i-1,j)$에다가 $x[i]$만 연장한 경우
- $E(i,j-1)$에다가 $y[j]$만 연장한 경우
- $E(i-1,j-1)$에다가 $x[i],y[j]$를 연장한 경우
첫 번째나 두 번째의 경우 무조건 edit distance가 1 늘어난다.
세 번째의 경우 $x[i],y[j]$가 다른 경우에만 edit distance가 1 늘어난다.
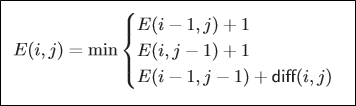
-
Algorithm:
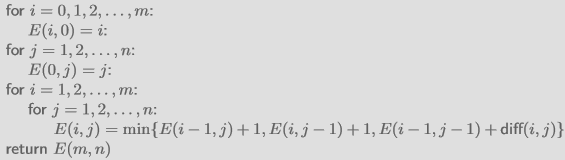
-
Base case:
- $i$ 또는 $j$가 0인 경우, 모든 문자가 다르므로 0이 아닌 쪽의 길이가 edit distance가 된다.
-
Time compleixty:
- Number of subproblems: $O(mn)$
- Time complexity for each subproblem: $O(1)$
- Total $O(mn)$
-
Knapsack
도둑이 보석가게에 배낭을 메고 침입했다
배낭의 최대 용량은 W이며, 이를 초과해서 보석을 담으면 배낭이 찢어질 것이다.
각 보석들의 무게와 가격은 알고 있다.
배낭이 찢어지지 않는 선에서 가격 합이 최대가 되도록 보석을 담는 방법은?
위 문제가 바로 Knapsack (배낭 채우기) 문제이다.
Knapsack 문제는 그 중에서도 보석을 중복해서 가져갈 수 있다고 가정하는 문제와, 반대로 중복해서 가져갈 수 없다고 가정하는 문제로 나뉜다.
간단한 예시를 통해 Knapsack을 이해해보자.
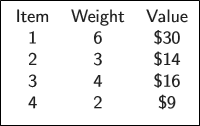
용량이 10인 가방과 4개의 물품이 주어졌을 때, 어떻게 담아야 value를 최대화 시킬 수 있을까?
우선 중복이 허용된 경우, (1,4,4)를 가져가는 게 최선이다.
만약 중복이 허용되지 않는다면, (1,3)을 가져가는 게 최선이다.
이제 대강 이해가 됐을테니, DP로 알고리즘을 정의해보자.
Knapsack with repitition
-
Ordering:
- Subproblems: $K(w)$ = 최대 Weight $w$를 가질 때 value of optimal selection
-
Relation:
$K(w)$는 $n$ 가지 경우로 나뉜다.
1번을 선택했거나, 2번을 선택했거나, 3번을 선택했거나… 이렇게 말이다. 따라서 다음과 같다.
$K(w)=max_{1\leq i\leq n}\lbrace K(w-w_i)+v_i: w_i\leq w \rbrace$
-
Algorithm:

-
Base case:
- weight가 0인 경우 아무것도 선택할 수 없으므로 0이다.
-
Time compleixty:
- Number of subproblems: $O(W)$
- Time complexity for each subproblem: $O(n)$
- Total $O(nW)$
-
Knapsack without reptition
-
Ordering:
- Subproblems: $K(w,j)$ = 최대 Weight $w$를 가지고, $j$번째 item까지 선택 가능할 때의 value of optimal selection
-
Relation:
$K(w,j)$는 두 가지 경우로 나뉜다.
- $j$번째 item을 선택하지 않을 경우: $K(w,j)=K(w,j-1)$
- $j$번째 item을 선택하는 경우: $K(w,j)=K(w-w_j,j-1)+v_j$
둘 중 최댓값을 골라야 하므로 max를 씌우면 다음과 같다.
$K(w)=max_{1\leq i\leq n}\lbrace K(w-w_i)+v_i: w_i\leq w \rbrace$
-
Algorithm:
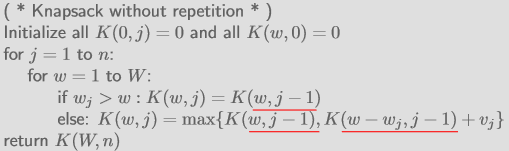
-
Base case:
- weight가 0인 경우 아무것도 선택할 수 없으므로 0이다.
- j가 0인 경우, 아무 item도 없으므로 0이다.
-
Time compleixty:
- Number of subproblems: $O(nW)$
- Time complexity for each subproblem: $O(1)$
- Total $O(nW)$
-
Chain Matrix Multiplication
행렬 곱은 순서에 따라 따라 연산수가 달라진다.
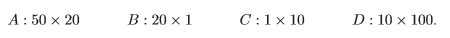
예를 들어서, $A\times B\times C\times D$를 계산한다고 해보자.

위처럼 어떤 걸 먼저 계산하냐에 따라서 총 연산수가 달라지게 된다.
우리가 구하고자 하는 것은 $A_1 \times A_2 \times A_3 \times \cdots \times A_n$의 최소 연산값이다. ($A_i$의 차원은 $m_{i-1}\times m_i$)
이걸 어떻게 DP로 풀 수 있을까?
잘 생각해보면 이 chain matrix mult를 이진 트리로 표현할 수 있다.
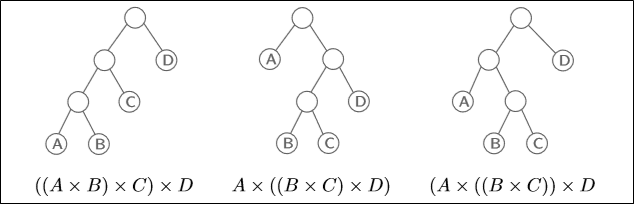
이 아이디어를 DP로 승화시켜보자.
-
Ordering:
- Subproblems: $C(i,j)$ = minimum cost of multiplying $A_i \times \cdots \times A_j$
-
Relation:
$C(i,j)$를 이진 트리로 표현하려면, 어떤 값을 기준으로 반으로 자르면 된다.
이 기준을 $k$라 하면, $C(i,k),C(k+1,j)$로 나눌 수 있겠다.
이때 반으로 자른 두 개의 matrix를 곱하는 비용도 고려해야 한다.
이 비용은 $m_{i-1},m_k,m_j$가 된다. ($A_i = m_{i-1}\times m_i$)
결국 $C(i,j)$는 첫 번째 subproblem + 두 번째 subproblem + subproblem을 곱하는 비용의 최소값이 된다.
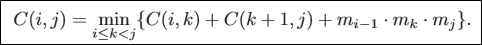
-
Algorithm:
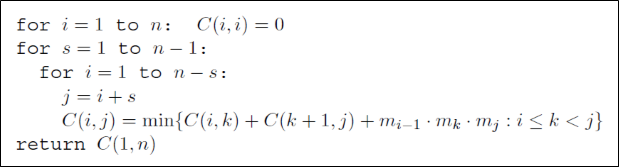
-
Base case:
- $i,j$가 같은 경우 단일 matrix이므로 0이다.
-
Time compleixty:
- Number of subproblems: $O(n^2)$
- Time complexity for each subproblem: $O(n)$
- Total $O(n^3)$
-
Shortest Reliable Paths
Given graph, find a shortest path from $s$ to $t$ that uses at most $k$ edges
-
Ordering:
- Subproblems: $dist(v,i)$ = shortest path from s to v that uses i edges
-
Relation:
i edge를 써서 가는 경로는 i-1 edge를 써서 가는 경로의 연장선이다.
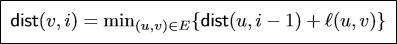
-
Algorithm:
-
Base case:
- $i=0$이면 0이다.
-
Time compleixty:
- Time complexity for each subproblem: $deg(v)$
- For each $i$, $\sum_{v} deg(v)=O(\lvert E \rvert)$
- Total $O(\lvert V \rvert \lvert E \rvert)$
-
All Pairs Shortest Paths
우리가 이전에 배웠던 것들은 모두 single source shortest path 알고리즘이다.
이걸 확장해서, all pairs shortest path를 구해보자.
가장 간단한 건 그냥 모든 노드에 대해서 single source shortest path 알고리즘을 돌리면 된다.
이 경우 $O({\lvert V \rvert}^2 \lvert E \rvert)$가 된다. (벨만 포드 사용)
DP를 이용해서 좀 더 빨리 풀어보자.
아이디어는 $dist(i,j)$에다가 거쳐갈 수 있는 노드의 집합이라는 한 가지 레이어를 추가하는 것이다.
$dist(i,j,\lbrace \rbrace)$부터 시작해서, 거쳐갈 수 있는 노드의 집합을 조금씩 확장해나가면서, 최종적으로 $dist(i,j,\lbrace 1,2,\cdots,n \rbrace)$을 구하는 것이다.
-
Ordering:
- Subproblems:
- $S_k = \lbrace 1,2,\cdots,k \rbrace$: 거쳐갈 수 있는 중간 노드들
- $dist(i,j,k)$ = shortest path from i to j using only nodes in $S_k$
- Gradually expand the set $S_k$ from $\phi$ to $V$
- Subproblems:
-
Relation:
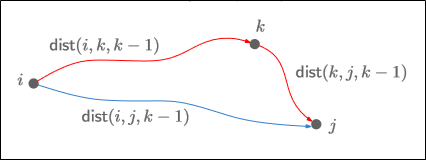
$S$를 확장시킨다는 아이디어를 적용해서, $S_{k-1}$에서 $S_k$로 확장을 해보자.
$k$를 거쳐갈 수 있다는 의미는 $k$를 거칠수도 있고 거치지 않을 수도 있다는 의미이다.
$k$를 거칠 경우 $k$를 경유해야 하므로 $dist(i,k,k-1)+dist(k,j,j-1)$이 된다.
$k$를 거치지 않을 경우 직통으로 오면 되므로 $dist(i,j,k-1)$이 된다.
-
Algorithm:

-
Base case:
- $S_0$의 경우, $(i,j)$ edge가 존재한다면 $l(i,j)$이고, 존재하지 않는다면 도달 불가능이므로 $\infty$이다.
-
Time compleixty:
- Number of subproblems: $O({\lvert V \rvert}^3)$
- Time complexity for each subproblem: $O(1)$
- Total $O({\lvert V \rvert}^3)$
-
The Traveling Salesman Problem
모든 노드를 한 번씩 방문하는 경로 중 최소 비용의 경로를 구해라는 문제이다.
이 문제는 아마 아이디어를 생각해내기가 꽤 어려울 것이다.
핵심 아이디어는 방문한 집합을 단계적으로 늘려가는 것이다.
-
Ordering:
- Subproblems:
- $C(S,j)$ = the length of shortest path from 1 to j, visiting each node in S exactly once
- Subproblems:
-
Relation:
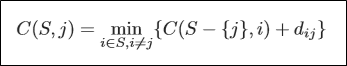
집합 $S$를 전부 방문해서 $j$에 도달했다는 것은 바로 직전에 $S$에서 $j$를 제외하고 모두 방문했고, 그 다음에 $j$를 들렀다는 의미가 된다.
따라서 $C(S,j)$는 $S$에서 $j$를 제외한 집합 $S-\lbrace j \rbrace$에서 최종적으로 어떤 노드 $i$를 방문한 다음 $j$로 오는 비용 중 최소값이 된다.
-
Algorithm:

-
Base case:
- 시작을 1번에서 하므로, $C(\lbrace 1 \rbrace, 1)$은 제자리에 있는 것이므로 0이다.
-
Time compleixty:
- Number of subproblems: $O(n2^n)$
- Time complexity for each subproblem: $O(n)$
- Total $O(n^2 2^n)$
-
Independent Sets in Trees
Find the largest independent set in the graph
만약에 주어진 그래프가 진짜 랜덤한 그래프라면 정말 풀기 어렵다.
그 대신, 우리는 graph가 tree인 케이스에 대해서만 다룬다.
간단한 예시를 통해 문제를 이해해보자.
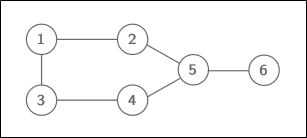
이 그래프의 largest independent set은 무엇일까?
여러가지 경우가 있겠지만, 1을 포함한다면 (1,4,6), 3을 포함한다면 (3,2,6) 정도가 있겠다.
구하는 방법은 상당히 간단하다.
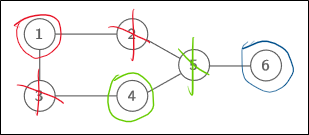
하나를 포함한다면 그와 인접한 노드들을 고를 수 없으니 제외하면 된다. 이걸 반복해서 값을 구할 수 있다.
이걸 DP로 표현해보자.
-
Ordering:
- Subproblems:
- $I(u)$ = number of nodes of the largest independant set of all subtrees below a node u
- Subproblems:
-
Relation:
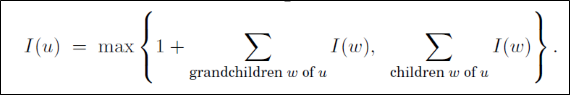
간단히 두 가지 경우로 나뉜다.
- u를 포함하거나
- u를 포함하지 않거나
u를 포함하는 경우 u의 자식들은 선택할 수 없으므로 u의 손자들의 I값을 게산한다.
반대로 u를 포함하지 않는 경우 u의 자식들의 I값을 계산한다.
-
Algorithm:
-
Base case:
- Leef node의 I값은 1이다
-
Time compleixty:
- Number of subproblems: $O(\lvert V \rvert)$
- With little care, $O(\lvert V \rvert + \lvert E \rvert)$
시간복잡도는 사실 좀 구하기가 까다롭다.
교과서의 경우 그냥 $O(\lvert V \rvert + \lvert E \rvert)$라고 적어놨지만,
교수님의 경우 $\sum_{v\in V} deg(v)\cdot 2 = O(\lvert E \rvert) = O(\lvert V \rvert)$라고 설명하셨다.
내 생각에는 교수님 풀이가 맞는 것 같다. 근데 두 답 모두 의미가 별 차이가 없으니, 대충 선형시간이다! 라고 알아두면 된다.
-
Weighted Interval Scheduling
이전에 greedy algorithm을 할 때 non-weighted interval scheduling 알고리즘에 대해서 배웠었다.
이제는 weight를 배울 차례이다.
Weight sheduling은 weight라는 새로운 평가 지표가 들어왔기 때문에 단순히 greedy algorithm을 쓸 수 없다.
대신 DP로 접근해보자.
-
Ordering:
- Subproblems:
- $OPT(j)$ = value of optimal solution to the problem consisting of jobs $1,2,\cdots,j$
- Subproblems:
-
Relation:

- $p(j)$ = last index of job which is compatible with j
Greedy algorithm의 아이디어를 채용해서 interval들을 finish time으로 정렬하자.
그러면 $OPT(j)$는 간단히 두 가지 경우로 나뉜다.
- job j를 선택하거나
- job j를 선택하지 않거나
job j를 선택할 경우 j 및 j와 incompatible한 job을 제외한 OPT를 구하면 된다.
반대로 job j를 선택하지 않을 경우 j를 제외한 OPT를 구하면 된다.

-
Algorithm:

-
Base case:
- $OPT(0) = 0$
- $OPT(1) = v_1$
-
Time compleixty:
- Number of subproblems: $O(n)$
- Time complexity for each subproblem: $O(1)$
- Total $O(n)$
-
Segmented Least Squares
드디어 마지막 문제다.
아마 least square에 대해서는 미적분 시간에 들어봤을테니 간략하게 설명한다.
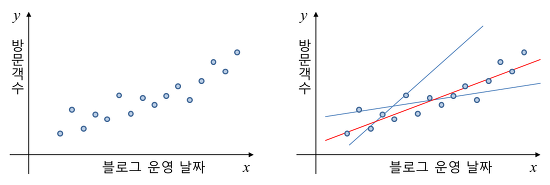
Least square method란, 위처럼 점들의 분포를 직선(또는 곡선)으로 근사하는 걸 의미한다.
이 문제에서 다룰 것은 polyline을 이용한 least square method이다.
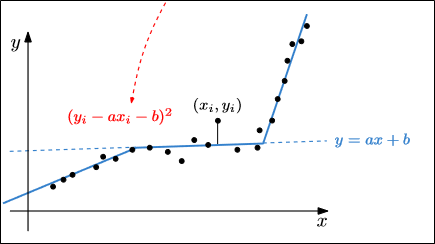
우리가 구하고자 하는 것은 에러를 최소화 하는 polyline이다.
이때 에러란 위 그림처럼 line과 point의 오차를 의미한다.
그런데 당연히 선을 늘리면 늘릴수록 오차가 줄어들 것이므로, 선을 추가하는 것에 패널티를 매겨야 무작정 선을 추가하지 않을 것이다.
따라서 선 한개당 $c$의 패널티를 매긴다.
그러면 최종적으로 $f(x)=E+c\cdot L$를 최소화 하는 polyline을 구하는 문제가 된다. (L은 line의 개수)
-
Ordering:
- Subproblems:
- $OPT(j)$ = minimum cost for points $p_1,p_2,\cdots,p_j$
- Subproblems:
-
Relation:
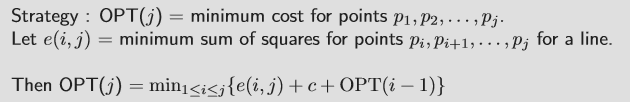
- $e(i,j)$ = minimum sum of squares for points $p_{i},p_{i+1},\cdots,p_j$
$p_1,p_2,\cdots,p_j$를 $p_i$를 기준으로 이등분 한다고 생각하자.
$p_i, \cdots, p_j$에 대해선 선을 하나 새로 만들어서 에러를 구할 것이다.
$p_1, \cdots, p_{i-1}$은 이전에 구해둔 값을 사용할 것이다.
이때, 선을 하나 새로 만들었으므로 선 만드는 패널티 값 $c$가 추가되어야 한다.
따라서 이를 전부 더하면 $e(i,j)+c+OPT(i-1)$이 되고, 이 중 최소값을 구하면 된다.
-
Algorithm:

-
Base case:
- $OPT(0) = 0$
-
Time compleixty:
- Number of subproblems: $O(n)$
- Time complexity for $e(i,j)$: $O(n)$
- Time complexity for each subproblem: $O(n^2)$
- Total $O(n^3)$
-
-
https://darkpgmr.tistory.com/56 ↩