[Algorithm] Greedy Algorithms (2)
이 글은 포스텍 오은진 교수님의 CSED331 알고리즘 수업의 강의 내용과 자료를 기반으로 하고 있습니다.
알고리즘 5주차 두 번째 강의 요약이다.
개인적으로 증명 부분은 이제까지 들었던 것들 중 가장 이해하기 어려웠었다.
사실 아직도 완벽하게 이해하지는 못했다.
몇 번씩 반복해서 읽다보면 언젠간 이해하지 않을까? ㅎ
아니면 이 글을 보는 누군가가 댓글로 좀 가르쳐줬으면 한다..
1. Path Compression
지난 포스트에선 Union-Find 자료구조에 대해서 배웠었다.
이번 포스트에서는 이 자료구조를 개선시키는 방법에 대해서 배울 것이다.
Union-Find의 시간 복잡도를 결정짓는 결정적인 요소는 바로 height이다.
지난 포스트에선 height를 줄이기 위해 union을 조금 복잡한 방식으로 했었다.
근데 이것도 tree가 커지면 별 소용이 없다.
그럼 어떻게 해야 아예 처음부터 tree의 height를 낮은 상태로 유지할 수 있을까?
생각해보자. 굳이 깊은 트리를 만들 필요가 있을까?
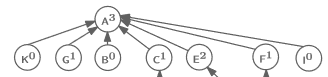
그냥 이렇게 height를 1로 유지해도 set을 표현하는 데에는 아무 문제가 없지 않을까?
바로 이 접근법이 오늘 우리가 배울 Path Compression이다.
Implementation
그럼 이걸 어떻게 구현해야 할까?
union을 살짝 수정해서 항상 height 1을 유지하면서 합치게 하면 될까?
슬프게도 그럴 순 없다.

보다시피 union은 root끼리만 붙일 수 있지, 다른 노드들을 움직일 수는 없기 때문이다.
그렇다면 남은 선택지는 하나다. find를 수정하자!
수정하는 방법은 간단하다. 탐색하면서, 겸사겸사 탐색하는 노드의 부모를 root로 바꿔버리면 된다.
이를 코드로 표현하면 다음과 같다.
function find(x)
if x != π(x)
π(x) = find(π(x)) ## x의 부모를 root로 바꿔라.
return π(x)
자 그럼 이 코드가 어떻게 돌아가는지 그림을 통해 알아보자.
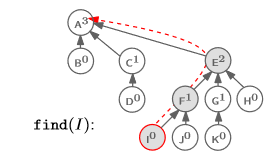
find(I)를 실행했다고 하자.
그러면 find(I)가 root에 도달할 때까지 재귀를 할 것이다.
그러다 재귀가 종료되면, 되감아 오면서 parent를 바꿀 것이다.
다시 말해, E, F, I 순서대로 parent를 바꾸게 된다는 것이다.
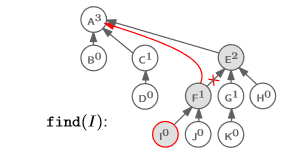
가장 먼저 E의 parent가 바뀌겠지만, 원래부터 root라서 영향은 없다.
그 다음으로 F의 parent가 root로 바뀐다.
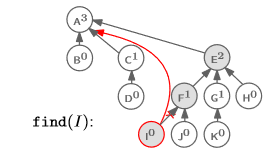
마지막으로 I의 parent가 root로 바뀐다.
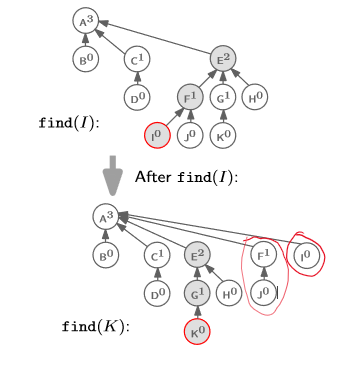
find(I)가 완료되고 나면 위와 같이 tree가 변형된다.
개념 자체는 간단하기 때문에 쉽게 이해했을 것이라 생각한다.
그럼 여기서 퀴즈!
이 다음에
find(K)를 하면 어떻게 될까??
정답은 아래에 있다.
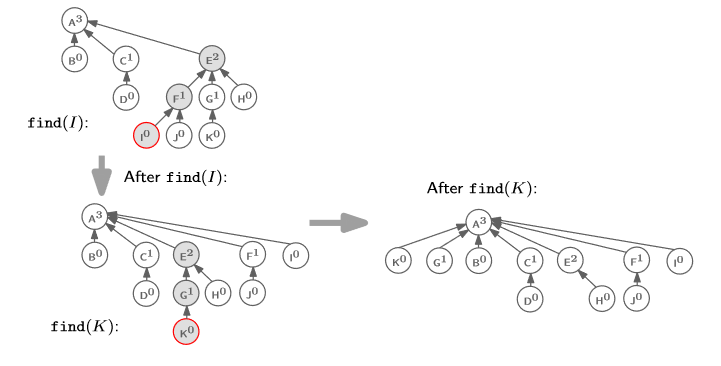
2. Time Complexity
이제 Path compression을 통해 얼마나 성능이 향상되었는지 알아보자.
$n$개의 element에 대해 $m$번의 find와 union을 돌린 상황의 total running time을 계산할 것이다.
우선 새로운 수를 하나 정의해야 한다.
-
$log^{*}n$
n을 1까지 끌어내리는데 필요한 $log$ 연산의 수
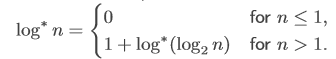
예를 들어 $log^{*}2^{2^{2}} = 1 + 1 + 1 = 3$ 이다.
왜 이런 수를 정의했냐면, rank를 grouping하기 위해서이다.
Rank를 $\lbrace k+1,k+2,\cdots,2^k \rbrace$의 형태의 group으로 나눠보자.
그럼 이렇게 나눠지게 된다.
$\lbrace 1 \rbrace,\lbrace 2 \rbrace,\lbrace 3,4 \rbrace, \lbrace 17,18,\cdots,2^{16} \rbrace, \lbrace 2^{16}+1, 2^{16}+2, \cdots, 2^{2^{16}} \rbrace, \cdots$
이제 기초작업은 끝났다. 본격적인 분석에 들어가보자.
잘 생각해보면, 결국 전체 연산 수는 전체 edge의 수와 같음을 알 수 있다.
이 edge를 Type-1과 Type-2로 구분해보자.

Type-1은 다른 그룹끼리 연결한 edge고, Type-2는 같은 그룹끼리 연결한 edge이다.
이 개념을 적용해서 전체 edge의 수를 다시 정의해보자.

이때 $x$는 각 그룹당 하나씩만 있다고 생각하면 된다.
그럼 이제 이것들을 계산해보자

총 그릅의 개수는 $log^{\star}n$개 이므로, 첫 번째 값은 당연히 $O(mlog^{\star}n)$이다.
두 번째 값이 살짝 이해가 안 갈 수도 있다.
우선 각 그룹 당 하나씩 있으므로 iteration은 $1$부터 $log^{\star}n$ 까지이다.
그리고 각 그룹의 element의 개수는 최대 $2^k$개 이다.
이게 조금 이해가 안 갈 수도 있는데, 이건 그냥 대충 최댓값을 때린거다.
엄밀하게 구하면 뭐 $2^k - (k+1) \cdots$ 복잡해지지만, 그냥 무조건 $2^k$ 보다는 작으니까 이렇게 잡은거다. 계산이 더 용이해지기도 하고.
그리고 rank가 $k$인 node의 수는 저번 포스트의 property 5에 의해 총 $n/2^k$개 이므로, 위와 같은 식이 나오는 것이다.
그렇게 계산해보면? 총 $O(mlog^{\star}n)$이 나오는 것이다.
PPT 밑에 있는 내용은 교과서에 적힌 접근 방식이다.
원리는 같은데, 너무 쓸데없는 소리가 많아서 이해하기가 힘들다.
한 번 심심하면 읽어보자.