[AI] Constraint Satisfaction Problems (1)
이 글은 포스텍 이근배 교수님의 CSED442 인공지능 수업의 강의 내용과 자료를 기반으로 하고 있습니다.
인공지능 3주차 첫 번째 강의 요약이다.
갑자기 난이도가 올라가서 놀랐다..ㅠㅠ
아직도 완벽하게 이해하진 못해서 꾸준히 수정할 예정이다.
1. Constraint Satisfaction Problems (CSPs)
우리가 이제까지 배웠던 알고리즘들은 다소 진부했다.
문제가 어떤 구조를 가지는지, 어떤 제약을 가지는지 관심이 없었다.
이로 인해 state의 내부 구조를 세부적으로 정의할 필요가 없었기 때문에 state를 그냥 internal structure가 없는 black box로 생각했다.
이제 state에 internal structure을 부여해보자.
State를 특정한 value가 할당된 variable들의 집합으로 보는 것이다.
여기에 variable간에 제약을 끼얹으면?
Constraint Satisfaction Problems (CSPs), 즉 variable 간에 제약이 있는 상황에서, 이런 제약을 모두 만족시키는 variable/value pair을 구하는 문제 가 된다.
이 정의로부터 CSP의 구성요소를 뽑아내보면,
-
$X$ : variable들의 집합 $\lbrace X_1, \cdots, X_n \rbrace$
-
$D$ : value의 domain의 집합 $\lbrace D_1, \cdots, D_n \rbrace$
-
$C$ : 제약 조건의 집합 $\lbrace C_1, \cdots, C_n \rbrace$
$C_i$ : $<scope, rel>$
-
scope : variable의 tuple
-
rel: variable들이 가질 수 있는 값의 관계(제약 조건)
-
ex) $X_1, X_2$가 {$A, B$} 값을 가질 수 있을때, $C_1$은 $X_1, X_2$이 같은 값을 가질 수 없다는 제약이라면 $C_1$ = <($X_1, X_2$), [$(A,B),(B,A)$])>
-
가 될 것이다.
이 정의를 바탕으로 state를 다시 정의하면, state란 {$X_1=V_1$, $X_2=V_2$, $\cdots$} 처럼 variable/value pair의 배열(= assignment)이 된다.
이때, 이 assignment를 세가지로 분류할 수 있는데 각각은
- consistent assignment: 어떠한 제약조건도 위반하지 않는 배열
- complete assignment: 모든 variable에 value가 할당된 배열
- partial assignment: 일부 variable만 value가 할당된 배열
이고, 곧 CSP의 solution이란 consistent, complete assignment라 할 수 있다.
이전처럼 goal까지의 path가 아닌 goal 자체를 구하는게 목적임에 주의하자!
아마 이것만 읽으면 뭔 소린가 싶을 것이다.
예시를 하나 보자.
Example: Map Coloring
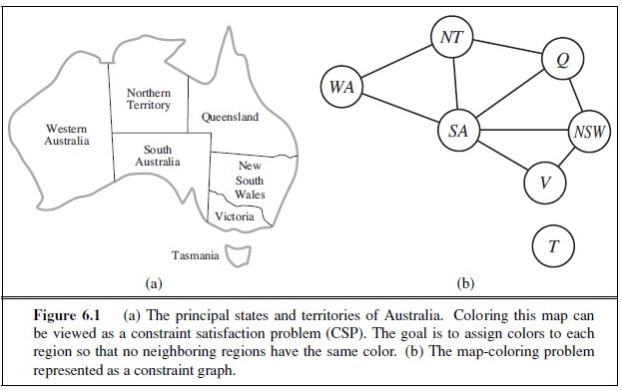
중학교때 자주 봤던 인접한 지역 다른 색으로 칠하기 문제를 CSP로 생각해보자.
빨간색, 초록색, 파란색 3가지 색깔이 주어진다면 아래와 같이 formalize할 수 있을 것이다.
-
$X$ : {WA, NT, Q, NSW, V, SA, T}
-
$D$ : {red, green, blue}
-
$C$ : 인접한 지역은 다른 색을 가져야 한다
- Implicit: {WA != NT, WA != SA, NT != NT, $\cdots$}
- Explicit: <(WA, NT), [(red,green),(red,blue), $\cdots$]>, <(WA, SA), [(red,green),(red,blue), $\cdots$]>, $\cdots$
그리고 이 CSP의 solution은 제약을 만족시키는 지역-색 pair의 배열을 찾는 것이 된다.
예를 들어 {WA=red, NT=green, Q=red, NSW=green, V=red, SA=blue, T=green} 이렇게 말이다.
이때, 이 배열을 어떻게 얻는지는 관심이 없다! CSP는 goal itself에만 집중하다는 것을 까먹지 말자.
이제 CSP가 무엇인지 이해했을 것이다!
참고로 이런 CSP를 (b)처럼 constraint graph로 시각화 할 수 있다.
각 노드는 variable을 의미하고, edge는 contraint를 의미한다.
Variations on the CSP formalism
일반적으로 CSP에 쓰이는 변수들은 이산적(Discrete)하고, 유한한 영역(Finite domain)을 갖고 있다.
여기서 한발 나아가면 무한한 영역(Infinite domain (integer, string…))을 가질 수도 있는데, 이 경우 제약 조건을 일일히 다 적을 수는 없으니 $V_1+2\leq V_2$와 같이 적는다. 여기까진 그나마 풀기 쉽다.
하지만, 현실 세계의 많은 문제들은 continous variable을 가진다. 예를 들어 허블 우주 망원경의 연구 스케쥴링이라던가… 다행히도 이런건 학부생 수준에선 안배운다 ㅎㅎ
또한 제약의 종류도 다양하다.
- Unary constraint: single variable을 제약 (SA != green)
- Binary constraint: pair of variable을 제약 (SA != WA)
- Higher-order contraint: 3개 이상의 variable을 제약
2. Standard Search Formulation
CSP를 정의했으니, 이제 문제의 답을 찾는 방법을 배울 시간이다.
이전에 planning에서도 그러했듯, CSP도 search problem이다.
다만 새로이 정의한 state의 개념을 적용해야 한다.
-
Inital state: the empty assignment, { }
-
Successor function: 아직 할당되지 않은 variable에 값을 할당하는 것
-
Goal test: 현재 assignment가 complete하며 consistent한가?
이렇게 말이다.
Contraint propagation
여기서 질문, 이전의 search와 CSP에서의 search가 가지는 가장 큰 차이점이 무엇일까?
바로, 제약이 존재한다는 점이다.
CSP search에서는 이 제약을 활용하여 variable에 할당가능한 value들의 가짓수를 줄일 수 있고, 이를 inference 또는 constraint propagation이라 부른다.
이 constraint propagation를 적용하기 위한 핵심 아이디어는 local consistency다.
local consistency란 간단히, subsets of variables가 제약을 만족하는 상황을 의미한다.
곧, 위에서 말한 제약을 활용하여 value들을 가지치기 한다는 것은, local consistency를 만족하도록 inconsistent value들을 제거해나간다는 의미이다!
이렇게 되면 무작정 search 하는 것보다 훨씬 빠르게 답에 도달할 수 있을 것이다.
아래는 local consistency의 종류들이다.
1. Node consistency
A single variable is node-consistent if all the values in the variable’s domain satisfy the variable’s unary constraints
Node consistency란 variable의 domain이 모든 unary constraints를 만족하는 상황을 말한다.
예를 들어 variable $V$가 domain { $1,2,3,4$ }를 가질때, $V\leq 3$ 이라는 제약이 주어졌다고 해보자.
이때, $V$가 node-consistent 하기 위해서는, $4$를 쳐내고, { $1,2,3$ } 만을 취해야 한다.
2. Arc consistency
A variable is arc-consistent if every value in its domain satisfies the variable’s binary constraints
Arc consistency란 variable의 domain이 모든 binary constraints를 만족하는 상황을 말한다.
가장 중요한 local consistency 다!
풀어서 쓰자면, 어떤 제약(arc) $(X_i, X_j)$ 가 있을 때, $X_i$가 $X_j$에 대해 arc-consistent 하다는 말은 $X_i$의 domain $D_i$의 모든 value에 대해서, $X_j$의 domain $D_j$에 해당 제약을 만족하는 value가 존재한다는 말이다.
이 arc consistency를 유지하기 위해서는 어떻게 해야할까?
제약 $(X_i, X_j)$가 있을 때, $D_i$의 value 중 이와 대응하여 제약을 만족시킬 수 있는 $D_j$ value가 존재하지 않는 value를 지우는 방법을 사용한다.
흔히 꼬리(tail)을 쳐낸다 라고 한다.
예를 들어, variable $X$가 { $1,2,3,4,5$ }를 가지고 $Y$가 { $1,2,3$ }을 가진다고 하자.
제약 $<(X,Y),X\leq Y>$ 가 있을 때, tail $X$가 arc-consistent 하기 위해서는 { $4,5$ } 를 쳐내고 { $1,2,3$ } 만을 취해야 한다.
AC-3
이런 류의 알고리즘 중 가장 자주 쓰이는 것이 AC-3 알고리즘이다.

AC-3 알고리즘은 chained-arc consistency를 적용하는 알고리즘이다.
이 말은, 제약 $(X_i, X_j)$를 평가하다가 $X_i$의 domain $D_i$에 변화가 생긴다면, $X_i$의 이웃 $X_k$와의 제약 $(X_k, X_i)$에 대해서도 평가를 진행한다는 것이다.
이제 time complexity를 구해보자.
domain size를 $d$, binary constraints의 수를 $c$라고 하자.
우선 각 arc $(X_i, X_j)$는 최대 $d$번 queue에 들어갈 수 있다.
왜냐하면, domain의 사이즈가 $d$이기 때문에 $d$번 이상 value를 제거할 수는 없기 때문이다.
또한 각 arc를 평가하는데에는 $d\times d$, 즉 $O(d^2)$이 걸린다.
이때 총 constraints의 수가 $c$이므로, 다 곱하면 $O(cd^3)$이다.
3. K-consistency
A CSP is k-consistent if, for any set of $k-1$ variables and for any consistent assignment to those variables, a consistent value can always be assigned to any $k$th variable
사실 K-consistency는 일종의 일반화이다.
$K=1$이면 node consistency, $K=2$이면 arc consistency $K=3$이면 -배우지는 않았지만- path consistency이다.
Strongly k-consistent
$k, k-1, k-2, \cdots, 1$까지, 모든 consistency가 만족되는 경우에 strong k-consistent라고 한다.
이게 만족되는 경우에는 상당히 간편하게 해를 구할 수가 있다.
$X_1$에 consistent value를 할당하면 2-consistent에 의해 $X_2$의 consistent value를 구할 수 있고, 또 3-consistent에 의해 $X_3$를 구할 수 있고… 이런 식으로 쭉 구해지기 때문이다.
3. Backtracking Search
Strong k-consistent 같이 정말 강한 local consistency가 주어지지 않는 한, constraint propagation 만으로 문제를 풀 수는 없다.
그래서 search를 해야하는데, 여기서는 한가지 방법, Backtracking search만을 배운다.
Backtracking search란 한 번에 한 개의 variable에만 할당하며, 만약 할당가능한 값이 없는 경우 backtrack, 즉 되돌아가는 DFS 알고리즘을 말한다.
![]()
backtracking search 알고리즘의 핵심은 local consistency ,SELECT-UNASSIGNED-VARIABLE 그리고 ORDER-DOMAIN-VALUES이다.
왜냐하면
local consistency: 어떻게 constraint propagation을 하느냐? (Filtering)SELECT-UNASSIGNED-VARIABLE: 어떤 variable을 먼저 뽑느냐? (Ordering)ORDER-DOMAIN-VALUES: 어떤 value를 먼저 assign 하느냐? (Ordering)
이 세가지에 따라 성능이 판이하게 차이가 나기 때문이다.
1. Filtering
1. Forward checking
Forward checking이란, assign한 variable을 head로 한 contraints에 대해 arc-consistency를 확인하는 방법이다.
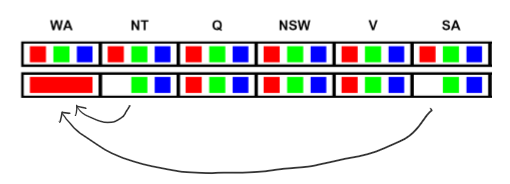
그림의 상황을 예로 들어보자.
WA에 red를 칠했으므로 (NT, WA), (SA, WA) 이 두가지 제약에 대해 arc-consistency를 체크하여 NT, SA에서 red를 지우게 된다.
그런데, 한가지 문제점이 있다.
바로 실패를 느리게 감지한다는 것이다.
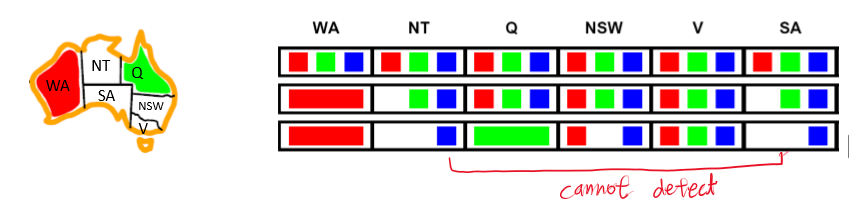
예를 들어 Q에 green을 칠할 경우, NT와 SA에 blue만 남아서 명백히 실패한 경우지만 (NT,SA)를 체크하지 않기 때문에 다음 단계에서나 이를 감지하게 된다.
2. Maintaining arc consistency (MAC)
MAC는 AC-3 알고리즘,즉 chaining-arc-consistency를 적용해 forward checking의 문제를 해결한 방법이다.
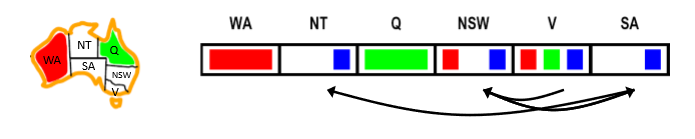
그림의 상황을 예로 들어보자.
Q에 green을 칠하게 되면 NT, SA, NSW에서 green이 사라진다.
만약 forward check라면 여기서 멈추겠지만, MAC는 한발 더 나가서 domain에 변경이 일어난 NT, SA, NSW에 대해 chaining-arc-consistency를 적용한다.
그러니까, (SA, NT), (NSW, SA), (V, NSW), $\cdots$ 등 domain에 변경이 일어난 variable을 head로 삼은 contraints에 대해 다시 arc-consistency를 확인한다는 것이다.
이렇게 되면 (SA, NT)에서 실패를 감지하므로, 다른 방법을 찾으러 되돌아간다(= backtracking).
보다시피 forward checking보다 실패를 먼저 감지하긴 하지만, 계산을 더 많이 해야하므로 느려질 것이다.
2. Ordering
Ordering은 크게 두 가지로 나뉜다.
Variable을 선택하는 순서, value를 선택하는 순서.
1. Minimum remaining values (MRV)
Choose the variable with the fewest legal left values in its domain
MRV (most contrainted variable 또는 Fail fast ordering 이라고도 부름) 은 SELECT-UNASSIGNED-VARIABLE 에서 가장 경우의 수가 적게 남은 variable부터 뽑자는 전략이다.
직관적으로 보면 당연하다.
한 variable을 빠르게 픽스시키면 search tree의 많은 부분을 잘라낼 수 있기 때문이다.
예를 들어 map coloring에서 Q를 green으로 고정시켜버리면 Q가 green이 아닌 node는 전부 볼 필요가 없어지므로 매우 효율적으로 searching을 할 수 있다.
2. Least constraining value
Given a choice of variable, choose the value that rules out the fewest choices for the neighboring variables in the constraint graph.
Least constraining value는 ORDER-DOMAIN-VALUES에서, 다른 variable에 최대한 적은 영향을 주는 value를 고르는 전략이다.
주의할 점은 value를 고르는 전략이라는 것이다! variable이 아니다!
이것도 직관적으로 보면 당연한데, CSP는 one solution을 찾는 것이 목표이므로 value들 중 가장 답이 될만한 것을 골라야 하기 때문이다.
만약 모든 solution을 찾는게 목표라면 이 전략이 그닥 쓸모가 없을 것이다.
4. Structure of problems
신기하게도 문제 구조 자체가 성능을 향상시키기도 한다.
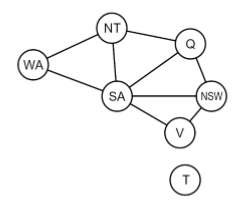
예를 들어, 위 경우 T가 아무 제약 없이 혼자 떨어져있기 때문에 T를 coloring 하는 것과 mainland를 coloring 하는 것은 서로 독립적인 문제가 되어버린다.
T에다가 뭘 칠해도 mainland에는 영향이 없다는 것이다.
1. Tree-structured CSPs
이렇게 성능을 향상시키는 구조가 흔치는 않지만, 아주 대표적인 예시로 tree-sturcture가 있다.
Tree는 acyclic, connected graph로, topological sort(linearlization)이 가능하다는 중요한 특성이 있다. (4주차 알고리즘 강의 노트 참고!)
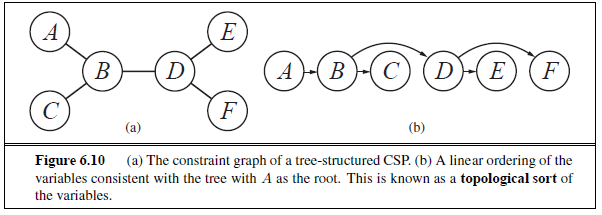
이렇게 topological sort를 하면 무슨 이점이 있을까?
바로 제약이 한 방향으로 쏠리기 때문에 chaining-arc-consistency 확인을 매우 효율적으로 할 수 있다는 점이다!

알고리즘을 보자.
우선 우측에서부터 하나씩 arc-consistency를 체크하고 있다. (MAKE-ARC-CONSISTENT)
AC-3 처럼 chaining을 하지 않고, 그냥 한번 쭉 순회만 해도 충분할까?
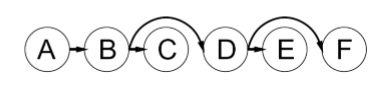
예를 들어, F를 체크했다고 해보자.
이 F가 이후에 또 체크될 일이 있을까? 전혀 그렇지 않다.
모든 제약이 좌측에서 우측으로 쏠려있기 때문에, 우측에서부터 하나씩 체크한다면 체크한 노드는 이후에 다시 체크할 필요가 없다.
곧, F를 체크하고 나면 F는 더 이상 필요가 없고, 그 다음 E를 체크하면 E도 더 이상 필요없고, 그 다음 C를 체크하면 C도 더 이상 필요가 없어진다.
이렇게 역방향으로 쭉 arc-consistent를 체크하고 나서, 정방향으로 순회하면서 답을 적어주면 된다.
이 획기적인 알고리즘의 time complexity는 얼마일까?
Node의 개수를 $n$이라고 했을 때 tree의 성질에 의해 edge의 수는 $n-1$개가 되고, 각 constraints를 확인하는데 $O(d^2)$이므로 총 $O(nd^2)$이 된다.
2. Cutset conditioning
문제가 죄다 tree structure면 참 좋겠지만, 세상은 그렇게 녹록치 않다.
그래서 나온 것이, 아예 문제를 tree-structure로 변형시켜버리는 괴랄한 알고리즘들이다.
이 중 첫번째가 cutset conditioning으로, variable 중 일부를 잘라내어 tree-stucture를 만드는 알고리즘이다.
이때 잘라낸 variable들을 cutset이라고 한다.
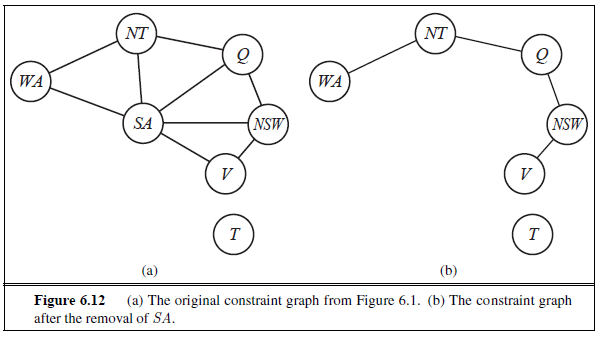
예를 들어, map coloring problem에서 SA를 잘라내면 문제가 tree-structure 로 변형된다.
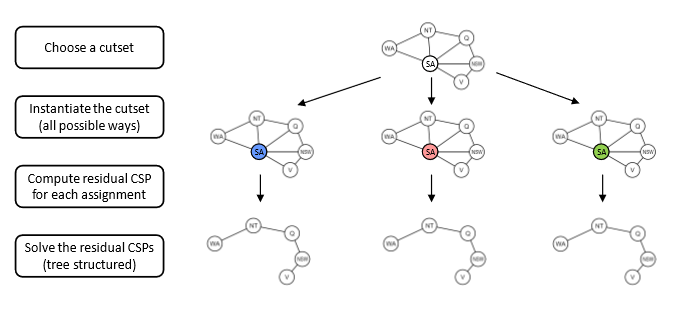
이제 이 문제를 풀기 위해서는, SA의 각 경우에 맞추어(blue, red, green) tree-structure problem을 풀면 된다.
그럼 time complexity는 어떻게 될까?
Cutset의 사이즈를 $c$라고 하자.
Cutset instantiation의 경우의 수는 $O(d^c)$.
Cutset의 각 경우에 맞추서 tree-stucture problem을 풀어야 하므로, 총 $O(d^c (n-c)d^2)$이 된다!
$c$가 작으면 상당히 효율적이라는 것을 알 수 있다.
3. Tree decomposition
두 번째 방법은 tree decomposition으로, 문제를 쪼갠 다음 그 문제들을 tree-structure로 엮는 알고리즘이다.
이때 쪼개진 문제들을 mega-variable이라고 부른다.
Divide and conquer의 일종이라 할 수 있겠다.
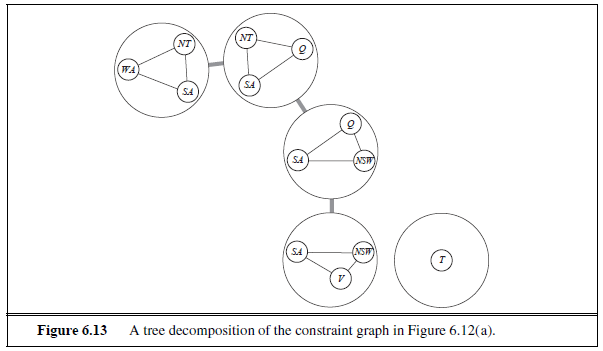
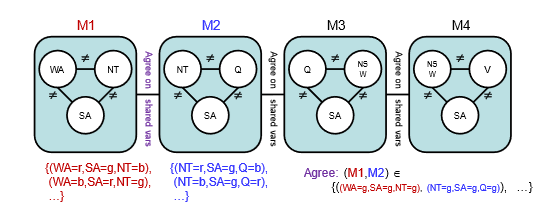
또 다시 map coloring을 예로 들어보자.
우선 문제를 총 4개의 mega-variable로 나눈다.
그리고 이 4개를 agree on shared var이라는 제약을 사용해 tree-structure로 엮었다.
이는 공통된 variable은 동일한 assignment를 가져야 한다는 제약이다.
푸는 방법은 우선 각 mega-variable의 assignment를 구하고, 그 다음 tree-strcture 알고리즘을 돌려서 최종 solution을 구하면 된다.