[OS] Synchronization (1)
이 글은 포스텍 박찬익 교수님의 CSED312 운영체제 수업의 강의 내용과 자료를 기반으로 하고 있습니다.
결국 가장 마지막에 작성하게 된 OS..
핀토스만 아니었어도 열심히 작성해줬을텐데 ㅎㅎ
약 3주 동안은 synchronization에 대해서 배운다.
이번 시간에는 synchronization이란 무엇인지, 그리고 어떻게 이를 이룰 수 있는지에 대해 배운다.
다음 시간에는 이번 시간에 배웠던 개념들을 코드로 구현하는 방법에 대해 배운다.
마지막 시간에는 좀 더 복잡한 multi object sychronization에 대해서 배운다.
내용이 많아보이지만 흐름이 명확하기 때문에 이해하기 어렵지 않다.
1. Race Conditions
Multi thread 환경을 구축하게 되면 concurrency(동시성) 문제가 반드시 뒤따라오게 된다.
이 concurrency 문제 중 가장 흔하게 발생하는 이슈가 race condition으로 인한 data inconsistency의 발생이다.
Race condition이란, 여러 thread가 경쟁적으로 shared state에 접근하는 탓에, 접근 순서에 따라 그 결과가 달라지는 상황을 말한다.
Race condition이 참 힘든 이유는 버그가 가끔 발생하기 때문이다. 대부분의 경우에서는 맞게 잘 돌아가다가, 가끔 이상한 결과가 나와서 사람을 환장하게 만든다.
2. Atomic Operation
Race condition을 막기 위해서는 각 thread의 접근이 atomic 하게 이뤄져야 한다.
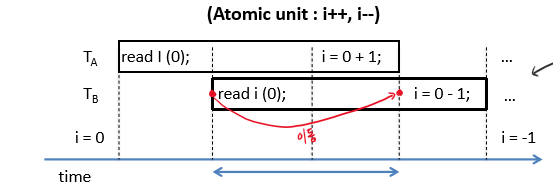
Atomic 하게 이뤄진다는 것은, 기능적으로 분할할 수 없거나 분할되지 않도록 보증된 동작이라는 뜻이다.
원자와 같이 분할할 수 없다는 것을 비유하여 이렇게 부르는 것이다.
말은 쉽지만, 실제로 atomic operation을 구현하는 것은 생각보다 쉽지 않다.
왜냐면 우선 프로그램의 동작 순서가 딱 정해져 있지 않기 때문이다.
전 포스트에서도 봤겠지만, thread scheduling은 언제나 일어날 수 있다.
이 말은 shared state에 여러 thread가 정해진 순서 없이 마구잡이로 접근할 수 있다는 얘기이다.
때문에 shared state를 구현할 때에는 가능한 모든 접근 방법을 고려해야만 한다.
그리고 아키텍쳐를 수강했다면 알겠지만, 최적화 때문에 instruction이 reordering 되기도 한다.
특정 구역을 atomic 하게 만들어놨더니, reordering 되어서 atomic이 깨질수도 있다는 것이다.
이를 막기 위해 memory barrier를 사용해 reordering을 제한하는 구역을 지정한다.
Too-Much-Milk Problem
Too-Much-Milk Problem은 atomic operation을 구현하는게 왜 어려운지 잘 보여주는 예제이다.

문제는 간단하다. 둘 중 한 명만이 우유를 사도록 구현해야 한다.
그러면 한 명이 우유를 사고 있다면 다른 한 사람은 사지 않도록 해야하고, 다시 말해 우유를 사는 행위를 atomic하게 만들어야 한다는 것이다.
차근차근 솔루션을 발전시켜나가보자.

가장 간단하게 생각할 수 있는 솔루션은 if문을 거는 것이다.
근데 이건 문제가 있다.
A, B가 동시에 우유를 살 수 있다.
다른 말로, mutual exclusion이 보장되지 않았다.

조금 솔루션을 발전시켜서, 내가 우유를 살 것이라는 노트를 남긴다고 해보자.
뭔가 타당해보이지만, 여전히 문제가 있다.
leave Note A → leave Note B 순서로 실행되면 아무도 우유를 살 수 없어진다.
다른 말로, starvation이 생긴다.

그럼 좀 더 조건문을 강화시켜서 둘 다 노트를 남긴 경우를 고려해주자.
이건 동작하긴 한다.
근데 딱 봐도 너무 복잡해보이고, 여러 thread로 확장시키기가 매우 어렵다.
게다가 기다리는 동안 의미없는 while문을 도는 busy waiting을 하므로 CPU 자원이 낭비된다.

그럼 한쪽은 기다리게 하고, 한쪽은 사게 만들면 어떨까?
되기야 하지만, thread마다 구현이 달라져야 한다는 점에서 매우 좋지 않은 방법이다.
Better Solution
Atomic opration을 일반 instruction의 조합으로 만드는 것은 봤다시피 정말 힘들다.
때문에, H/W 레벨에서 atomic load and store을 지원해줘야만 한다.
나중에 제대로 배우겠지만, 이를 이용한 기법이 바로 lock이다.

lock을 이용한 솔루션은 위와 같다.
위 솔루션은 mutual exclustion을 보장하며, starvation이 없고, busy waiting도 없는.. 아주 완벽한 솔루션이다.
3. Shared Object
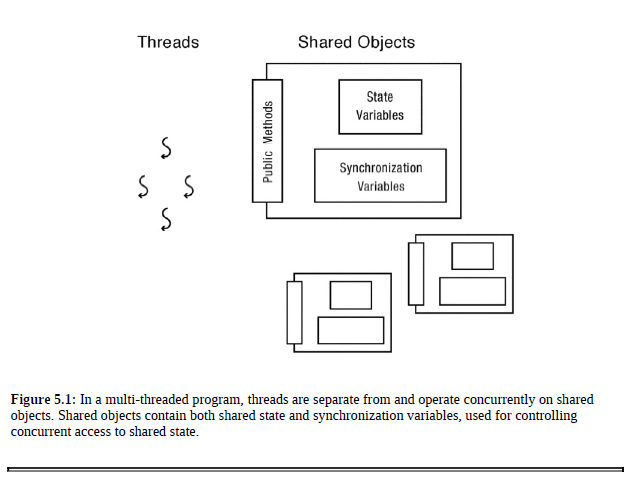
Multi-threaded program을 만드는 방법은 단순히 죄다 atomic load and store으로 구현하는 것을 넘어, OOP 개념을 적용해 모듈화하는 것으로 진화했다.
이 방법에 따르면, multi-threaded 프로그램은 shared object들과 이를 이용하는 여러 thread들로 나눌 수 있다.
이때 shared object란 여러 thread들이 마치 single thread object에 접근하듯이, 안전하게 접근할 수 있는 객체를 의미한다.
이런 객체를 구현하기 위해서는, synchronizing detail을 숨기고 thread에게 클린한 인터페이스를 제공해주어야만 한다.
우리는 앞으로 이 shared object를 구현하는 방법에 대해서 배울 것이다.
한 가지 주의할 점은, 객체라는 단어 때문에 shared object가 언어 종속적인 개념이라고 생각하면 안된다는 것이다.
객체라는 것은 일종의 제약이지, 뭔가 특별한 개념은 아니다.
대표적인 절차지향 언어 C에서도 shared object를 구현할 수 있다.
synchronization variable과 state variable을 struct로 묶고, 이 struct를 다루는 몇 가지 function을 제공해주면 그게 shared object다.
핀토스를 떠올려보면 이게 무슨 소리인지 이해할 수 있을 것이다.
다만 강의에서는 편의를 위해 객체지향 언어인 C++ / Java 의 문법을 기초로 서술하고 있다.
Layered Structure
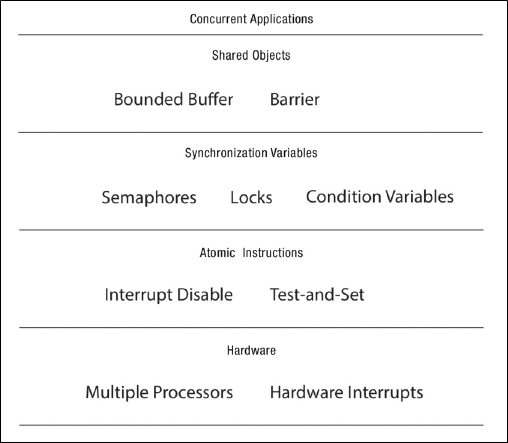
Shared object는 3가지 layer로 이루어져있다.
- Shared objects layer
- Interface. Provides Application-specific logic and hide internal implementation details.
- Synchronization variables layer
- A data structure used for coordinating concurrent access to shared state.
- Atomic Instructions layer
- Atomic proccessor-specific instructinos used by synchronization variables.
우리가 오늘 배울 것은 lock, condition variable, semaphore의 개념이다.
Lock
Lock은 mutual exclusion을 제공하는 synchronization variabe이다.
다시 말해, 한 thread가 lock을 소유하고 있으면 다른 thread들은 해당 lock을 소유할 수 없도록 하는 것이다.
Lock은 두 가지 method를 제공한다.
Lock::acquire- wait until lock is free, then take it
Lock::release- release lock, waking up anyone waiting for it
Lock::acquire은 critical section에 진입하기 전 lock을 소유하기 위해 쓰이고, Lock::release는 section에서 나갈 때 lock의 소유를 포기하기 위해 쓰인다.

예를 들어 synchronized queue를 구현한다고 해보자.
이 queue의 shared state인 queue에 접근하는 것은 exclusive해야 하므로, 접근 전에 항상 Lock::acquire을 통해 lock을 얻어야 한다.
그리고 접근이 끝났다면, 다른 thread에게 기회를 줘야 하므로 Lock::release를 통해 lock을 풀어줘야 한다.
Condition Variable
그런데 만약, 위의 예제의 RemoveFromQueue에서 queue에 어떤 것이 들어올 때까지 기다린 다음에 동작을 수행하게 하려면 어떻게 해야할까?
이 기능을 구현한 것이 condition variable이다.
Condition variable은 thread를 잠들게 하거나, 자고 있는 thread들을 깨우는 기능을 지원한다.
이를 위해 자고 있는 thread들을 저장하는 queue가 있으며, 이에 접근하는 3가지 method를 제공한다.
어떤 함수든 간에 실행하기 전에 lock을 소유하고 있어야 한다는 사실을 잘 기억하자.
Wait()- release lock, go to sleep, re-acquire lock
Signal()- wake up a waiter, if any
Broadcast()- wake up all waiters
주의 깊게 봐야하는 것은 wait() 함수이다.
잠들기 전 lock의 소유를 해제해야 내가 잠들고 난 후 다른 thread가 lock을 얻을 수 있을 것이므로, 우선 release lock을 하고 잠에 들어야 한다.
이때 이 동작은 atomic해야 한다! 그렇지 않으면 release lock과 sleep 사이에 다른 thread가 끼어들어 문제를 일으킬 수 있다.
그리고 잠에서 깨어나고 나면, 다시 lock을 얻어야만 critical section에 진입할 수 있으므로 re-aquire을 해야만 한다!
추가로 기억해야 할 condition variable의 중요한 특성은 memoryless이다.
Condition variable은 이전에 signal이 왔다는 사실을 저장하지 않는다. 따라서, wait은 이전에 signal이 왔던 안왔건 무조건 thread를 잠들게 해야한다.

자 그럼 synchronized queue 예제를 수정해보자.
RemoveFromQueue에서 queue에 아무것도 없으면 wait을 해서 들어올 때까지 기다리고 있다.
만약 AddToQueue에서 다른 thread가 queue에 item을 넣어주면서 signal을 보내면 기다리고 있던 thread 깨어나서 item을 지우게 된다.
그럼 근데 while을 왜 쓰고 있는걸까?
Mesa / Hoare style semantic
생각해보자. thread P가 signal()을 통해 thread T를 깨웠을 때, P가 계속 실행되어야 할까? 아니면 P가 멈추고 T가 실행되어야 할까?
전자가 mesa style semantic이고, 후자가 hoare style semantic이다.
Mesa style은 waiter를 ready list에 넣고, signaller가 계속 lock과 processor를 소유한다.
반대로 Hoare style은 waiter에게 lock과 processor를 모두 주고, signaller는 sleep한다.
대부분은 mesa style로 구현한다고 한다. 이 책도 mesa style을 전제로 하고 있다.
이걸 갑자기 왜 설명했냐면, 둘 중 뭘 쓰냐에 따라 while을 쓸지 안 쓸지가 달라지기 때문이다.
Mesa style의 경우 waiter가 바로 깨어나지 않기 때문에, 대기하는 동안 다른 thread에 의해 condition이 깨질 가능성이 존재한다.
따라서 깨어났을 때 다시 한 번 condition을 체크해야 하기 때문에 while을 사용하는 것이다.
반면 Hoare style은 곧바로 waiter가 일어나기 때문에 다시 condition을 체크할 필요가 없어 if만 사용해도 되는 것이다.
Spurious wakeup
그런데 대부분의 OS에서는 while문을 사용하라고 권장한다. 왜일까?
이는 spurious wakeup이라는 것 때문이다.
Spurious wakeup이란, signal을 하지 않았음에도 불구하고 thread가 깨어나버리는 현상을 말한다.
만약 if를 써버리는 바람에 멋대로 깨어난 thread가 진짜 멋대로 데이터를 수정해버리면 상상하기도 싫은 대참사가 벌어질 것이다.
그래서 항상 while을 씌우는 것이 좋다!
Semaphore
Semaphore는 일종의 일반화된 lock이다.
Semaphore는 non-negative integer를 가지고 있고, 이를 수정하는 두가지 방법을 제공한다.
P()- value가 양수가 될 때까지 기다렸다가 1을 감소시킨다.
V()- value를 1 만큼 증가시키고, P에 의해 잠들었던 thread를 깨운다.
Semaphore는 독특하게 초기값이 어떻게 되냐에 따라 두 가지 용도로 사용될 수 있다.
- 1로 초기화 한 경우

이 경우 lock처럼 mutual exclusion을 구현할 수 있다.
- 0으로 초기화 한 경우

이 경우 condition varaible처럼 thread가 특정 조건을 기다리게 만들 수 있다.
이렇게 어떤 thread가 뭔가가 일어날 때까지 기다리게 만드는 것을 scheduling constraints라고 한다.
Semaphore로 어떻게 scheduling contraints를 구현하는지 살짝 감이 안잡힐 수도 있다. 아래의 예제를 보자.

이렇게 코드를 구성하면 그 결과가 어떻게 될까?
무조건 T1, T2, T3 순서대로 끝나게 된다.
읽다보면 아마 이런 의문이 들 것이다.
semaphore 안쓰고 그냥 lock이랑 condition variable로 대신해도 되지 않나?
맞다. 실제로 일부 경우를 제외하고는 잘 쓰지 않는다. 아예 책에서는 harmful이라고 표현하고 있기도 하고.
다만 핀토스에서 이를 사용하여 synchronization을 구현하고 있으므로, 제대로 이해해두는 편이 나중에 핀토스 짤 때 편할 것이다.
Producer-Consumer
Semaphore와 관련된 굉장히 중요한 producer-consumer 라는 문제가 있다.
문제를 간단히 요약하면 다음과 같다.
buffer에 값이 있다면 이를 소모하는 consumer와, buffer에 빈 슬롯이 있다면 값을 집어넣는 producer를 구현하여라!
문제를 풀기 위해 필요한 semaphore가 무엇인지 생각해보자.
Consumer는 버퍼에 값이 있는지 체크하는 semaphore가 필요하겠고,
Producer는 버퍼에 빈 슬롯이 있는지 체크하는 semaphore가 필요할 것이다.
또한 exclusive한 buffer 접근을 위한 semaphore가 필요할 것이다.
이걸 적절히 잘 이용해서 구현하면 된다!
실제 구현은 아래와 같다.


-
empty: 버퍼에 빈 슬롯이 있는지 체크하는 semaphore
-
full: 버퍼에 값이 있는지 체크하는 semaphroe
-
mutex: buffer 접근을 위한 semaphore
아마 쭉 읽어보면 무슨 말인지 금방 이해할 수 있을 것이다.
그런데 왜 empty 값이 BUFFER_SIZE는 조금 이해하기 어려울 수도 있다. 수업시간에 질문이 들어오기도 했고.
이게 사실 empty라는 이름이 붙어있어서 헷갈리는 것이다.
empty는 비었다 / 아니다 를 판단하는 게 아니라, 정확하게는 비어있는 슬롯의 개수를 의미한다.
곧, BUFFER_SIZE의 의미는, 초기 슬롯이 BUFFER_SIZE만큼 있다는 얘기이다.
이 말은 producer가 연속적으로 empty.P()를 BUFFER_SIZE 번 부를 수 있다는 것이다.
그러다가 empty 값이 0이 되면, 그때는 empty slot이 생길때까지 (empty.V()를 부를때까지) 대기하는 것이다.
반대로 그럼 full은 초기값은 0이지만, BUFFER_SIZE까지 클 수 있는 것다는 것을 이해할 수 있겠는가?
헷갈리지 말자! Semaphore는 초기값을 1 이상으로 줘서 여러번 P()를 부르게 할 수 있다!!
Designing Shared Objects
위에서 배운 내용을 종합하여 shared object를 구성하는 방법을 서술하면 다음과 같다.
- Add a lock
- Add code to
acquireandreleasethe lock - Identify and add condition variables
- Add loops to wait using the condition variables
- Add
signalandbroadcastcalls
Monitors
일부 프로그래밍 언어는 shared object 자체를 지원하기도 한다. 예를 들어 java의 synchronized 키워드라던가.
이 경우의 shared object를 흔히 monitor라고 부른다.
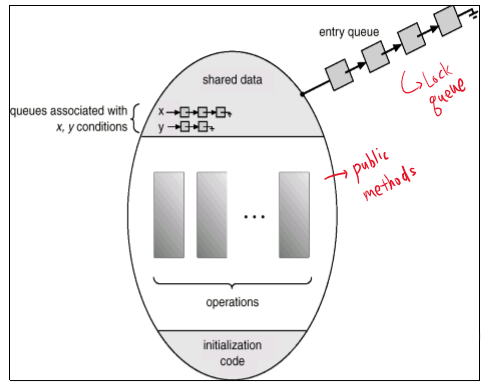
Monitor는 위 그림처럼 shared data, condition varriables, operations, intialization functions, lock queue 로 구성되어 있다.
재밌는 점은 lock이 implicit하다는 점이다.
곧, 위에서 한 것처럼 일일이 lock-acquire, lock-release하지 않아도, 알아서 잘 mutual exclusive를 지원해준다.

그래서 monitor의 condition variable은 인자로 lock을 받지 않는다.
대신, priority number라는 것을 받아, 나중에 깨울 때 이 숫자가 작은 thread부터 먼저 깨운다.