[Algorithm] Greedy Algorithm (3)
이 글은 포스텍 오은진 교수님의 CSED331 알고리즘 수업의 강의 내용과 자료를 기반으로 하고 있습니다.
이번 포스트의 주제는 greedy algorithm 을 쓰는 알고리즘들을 소개하는 것이다.
Greedy algorithm은 이해하기는 쉬운데, 증명이 참.. 쉽지 않다.
작년에 전산수학 중간고사로 이상한 greedy algorithm 증명하는게 나왔었는데, 결국 못 풀어가지고 전산수학을 드랍한 슬픈 기억이 있다.
그래서 지난 학기에 재수강했는데, A- 나와서… 교수님을 볼 낯이 없다… 전공에서 처음으로 A-를 받아봤다.
근데 문제는 알고리즘도 A- 뜰 것 같다. 아니 A- 떠주면 감사한건가..?! 도통 이런 수학적인 내용은 나랑 안맞는 것 같다.
여하튼, 이번 포스트는 전체적으로 별 내용이 없다. 그냥 알고리즘 소개에 가깝다.
그냥 Greedy algorithm은 이렇게 증명하는구나~ 정도의 흐름만 캐치하면 된다.
1. Interval Scheduling
문제의 상황은 이렇다.
여러 개의 job 들이 있다.
이때, 각 job $j$는 $s_j$에 시작해서 $f_j$에 끝난다고 하자.
우리의 목표는 서로 겹치지 않는 스케쥴을 짜서, 최대한 많은 job을 수행하는 것이다.
이걸 greedy로 접근하려고 하면, 4가지 접근법이 떠오를 것이다.
- Earliest start time
- Earliest finish time
- Shortest interval
- Fewest conflicts
이 중에 뭘 골라야 할까?
잘 생각해보면, earliest finish time을 제외하고 나머지 3개는 반례가 존재한다.
-
Earliest start time

가장 빨리 시작하지만 가장 늦게 끝나는 job이 있다고 하면, Earliest start time 알고리즘은 이걸 선택하겠지만 명백하게 이 선택은 optimal 하지 않다.
-
Shortest interval

수행 시간이 짧긴 하지만 충돌을 많이 일으키는 job이 있다고 하면, Shortest interval 알고리즘은 이걸 선택하겠지만 명백하게 이 선택은 optimal 하지 않다.
-
Fewest conflicts
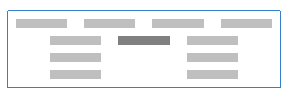
살짝 극단적이긴 한데, 위 그림같은 케이스라면 맨 위의 네 줄을 뽑는게 더 이득이기 때문에 이 알고리즘은 optimal 하지 않다.
그러면 earliest finish time은 optimal하다는 얘기인데.. 정말일까? 증명해보자.
참고: PPT라는 약간 다른 방식이다.
Earliest finish time으로 선택한 $r$개의 job을 각각 $i_1, i_2, \cdots, i_k$이라고 하고,
실제 optimal solution의 job을 $j_1, j_2, \cdots, j_m$ 라고 하자.
우선 보조정리로, 모든 $r$번째 job에 대해 $f(i_r)\leq f(j_r)$가 성립함을 보여야 한다.
다시말해, greedy solution의 job은 대응되는 optimal solution의 job보다 빨리 끝난다는 것이다.
Induction으로 증명할 수 있다.
-
Base case
greedy solution은 가장 빨리 끝나는 것을 선택하므로 당연히 $f(i_1)\leq f(j_1)$
-
Induction step
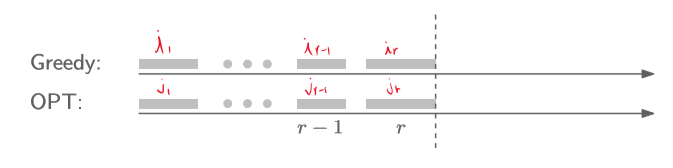
$r$번째에서 claim이 성립한다고 가정해보자.
$r+1$번째에서 claim이 성립함을 귀류법을 통해 증명해보자.
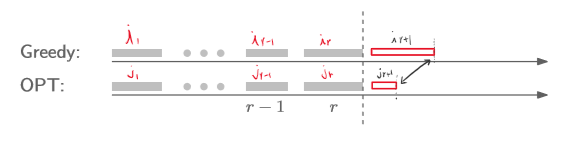
$f(i_{r+1})\geq f(j_{r+1})$라고 가정해보자.
이때 $f(i_{r})\leq f(j_{r})$이므로, $j_{r+1}$은 $i_r$과 충돌하지 않기 때문에, 우리의 알고리즘은 $j_{r+1}$를 고르지 않을 이유가 없다.
따라서 $f(i_{r+1})\leq f(j_{r+1})$이고, inductin에 의해 claim은 성립한다.
이 보조정리로부터 $k=m$임을 보이자.
$m>k$라고 가정해보자.
그러면 $j_{k+1}$은 있고 $i_{k+1}$은 없다는 얘기인데.. 이게 가능할까?
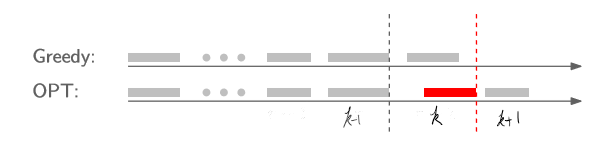
아까 증명한 보조정리에 의해 $f(i_{k})\leq f(j_{k})$이므로, $j_{k+1}$은 $i_{k}$와 충돌하지 않는다.
그러면 당연히 우리의 알고리즘은 $j_{k+1}$을 선택할 것이므로, $m>k$는 불가능하다.
따라서 $m=k$이다!
간단하지만, greedy algorithm을 어떤 식으로 증명해야 하는지 감을 잡는데에는 꽤 괜찮은 예제이다.
2. Interval Partitioning
1번과 굉장히 비슷한 문제이다.
문제의 상황은 이렇다.
n개의 강의들이 있다.
이때 강의 $j$는 $s_j$에서 시작해서 $f_j$에 끝난다고 하자.
우리의 목표는 강의들을 겹치지 않게 배정할 수 있는 최소한의 강의실의 수를 구하는 것이다.
결론적으로 아래의 earliest start time 알고리즘을 통해 구할 수 있다.
Sort lectures by their staring time
d = 0
for j = 1 to n
if (lecture j is compatible with some classroom k)
shedule lecture j in classroom k
else
allocate a new classroom d+1
schedule lecture j in classroom d+1
d = d+1
return d
이게 왜 optimal 한지 증명해보자.
각 step에서의 선택이 항상 optimal하다는 것을 보일 것이다.
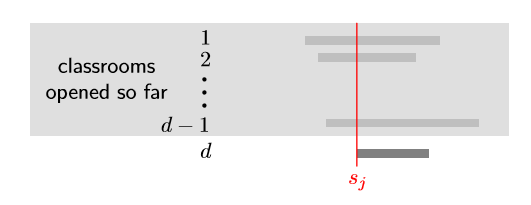
$d$번째 강의가 다른 $d-1$개의 강의들과 겹쳐서 classroom $d$가 생성되었다고 해보자.
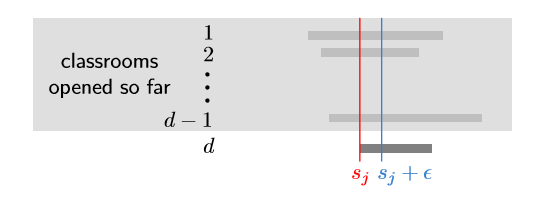
초반에 소팅을 했기 때문에 겹치는 $d-1$ 강의들은 모두 $d$번째 강의보다 빨리 시작하며, 끝나는 시점이 $d$번째 강의가 시작하는 시점보다 뒤에 있다.
이 말은 $s_j+\epsilon$ 시점에 $d$개의 겹치는 강의가 있다는 것이다.
따라서, 우리는 $d$ 강의를 할당하는 데 최소 $d$개의 강의실이 필요하다. 증명 끝.
정말 별 거 없다.
그럼 시간 복잡도는 어떻게 될까?
우선 소팅하는데 $O(nlogn)$.
한편 if (lecture j is compatible with some classroom k)에서 선택하는 classroom $k$는 가장 빨리 강의가 끝나는 classroom이어야 한다.
이걸 구현하기 위해 heap (priority queue)를 쓴다고 하면 뽑는데 $O(logn)$이므로, 총 $O(nlogn)$.
따라서 총합 $O(nlogn)$이다.
3. Huffman Encoding
어떤 string을 binary로 인코딩하는 가장 효율적인 방법이 무엇일까?
그러니까 예를 들어 알파벳 $A, B, C$로 이루어진 string $AABBCCABCCDA…$ 를 어떻게 binary 0, 1로 표현할 수 있을까?
어게 어려운 점은 디코딩이 unique string을 뱉어내야 한다는 점이다.
예를 들어 $A=0, B=1, C=10$ 이런 식으로 인코딩 해버리면, 0101이 $ABAB$ 또는 $ACB$, 두 가지로 디코딩 되어버린다. 이러면 올바른 인코딩이 아니다.
가장 쉬운 방법은 각각의 알파벳에 고정 길이 binary string을 할당해버리는 것이다.
예를 들어 ${A=00,B=01,C=10}$ 이런 식으로 말이다.
근데 이것보다 더 효율적인 방법이 없을까?
잘 생각해보자. 굳이 고정 길이를 쓸 필요가 있을까?
많이 나오는 문자는 짧은 길이의 bianry로 인코딩하고, 적게 나오는 문자는 긴 길이의 binary로 인코딩 하면 조금 더 효율적이지 않을까?
이게 huffman encoding이다.
이 알고리즘의 접근법을 차근차근 밟아가보자.
우선 가변 길이 인코딩을 쓰기 위해서는 코드(인코딩된 문자)가 prefix-free해야만 한다.
이게 무슨 말이냐면, 그 어떤 코드도 다른 코드의 prefix가 아니라는 말이다.
예를 들어 $A=0, B=1, C=10$는 $B=1$이 $C=10$의 prefix이므로, 이는 prefix-free가 아니다.
Huffman encoding은 이 prefix-free 인코딩을 바이너라 트리로 생각한다.
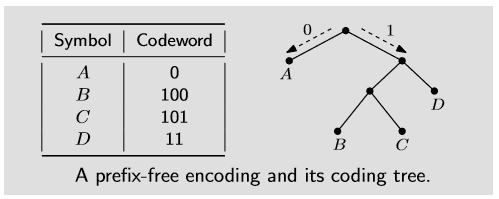
각 leaf에 문자를 할당하고, 좌측으로 갈 때마다 0, 우측으로 갈 때마다 1을 줘서 코드를 만드는 것이다.
아마 이렇게 만들어지는 코드 집합이 prefix-free임을 쉽게 눈치챌 수 있을 것이다.
자 그럼, 많이 나오는 문자는 짧은 길이의 코드를 주고 적게 나오는 문자는 긴 길이의 코드를 주기 위해서는 어떻게 leaf를 배치해야 할까?
직관적으로, 적게 나올 수록 더 깊은 곳에 위치해야 할 것이다.
이를 알고리즘으로 표현해보면 다음과 같다.
문자 n개의 출현 빈도를 각각 $f_1,f_2,\cdots,f_n$이라고 하자.
-
$f_1,f_2,\cdots,f_n$를 가지고 priority queue를 만든다.
-
Queue에서 가장 빈도수가 작은 두 개, $f_i, f_j$를 뽑는다.
-
이 두 개를 합쳐서 tree를 만든다.
-
두개를 합친 값인 $f_i, f_j$를 다시 queue에 넣는다.
-
1-3 을 $n-1$번 반복한다.
대충 이런 느낌의 트리가 나온다.
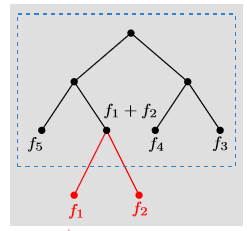
아래는 이걸 수도코드로 표현한 것이다.

원래대로라면 이제 optimality를 증명해야 하는데.. 사실 이게 증명까지 할 필요가 없을 정도로 당연하다.
교과서에도 딱히 증명이 적혀있지도 않고.
그냥 시간 복잡도나 계산해보자.
Priority queue로 binary heap을 쓴다고 해보자.
두 번의 deletemin, 한 번의 insert를 총 $n-1$번 하므로, $O(nlogn)$이다.